
Как подключить антенну и настроить каналы?
Ничего сложно нет. Антенну лучше всего устанавливать на улице и крепить на самую высокую часть дома. В многоквартирных домах, если есть возможность – можно провести кабель на крышу. Далее подключаем кабель к антенне и втыкаем второй конец кабеля к телевизору, если у него есть DVB-T, DVB-T2 поддержка.
Если нет – то берём покупаем цифровой приёмник и кабель от антенны вставляем в дополнительный ресивер. Еще очень важный момент – направить антенну в сторону вышки для более хорошего сигнала. Если вы подключаете напрямую к телевизору, то чтобы настроить каналы, просто заходим в меню телика и выбираем раздел «Цифровое телевидение». Далее установите поиск каналов в автономном режиме. Качество настроенных каналов будет зависеть от расстояния между вышкой и антенной, препятствий между ними и отправителем сигнала.
Streaming SIMD Extensions (SSE)
Introduction
SSE was introduced in the Pentium III and offered an additional 70 instructions to the Intel Instruction Set. SSE instructions can help give an increase in data thouroughput due to Single Instruction, Multiple Data (SIMD) instructions. These instructions can execute a common expression on multiple data in parallel.
There are 8 (16 in 64-bit mode) XMM registers (XMM0-7(15)) that come with SSE, and they are 128-bit registers. Certain SSE instructions (movntdqa, movdqa, movdqu, etc…) can load 16 bytes from memory or store 16 bytes to memory in a single operation. Also, SSE introduces a few non-temporal hint instructions (movntdqa and movntdq) that allow one-shot memory locations to be stored in non-temporal memory so those location references to do not pollute the small on-chip caches.
Since this change added new registers, it is disabled by default as the typical operating system of that time was not yet able to save those registers on a task switch. To support SSE, you will need to implement separate code paths for saving and restoring SSE state (as those instructions will cause an exception on processors that do not support it), and handlers for the new exceptions. After that, you can tell the CPU to enable SSE use in userland tasks.
Checking for SSE
to check for SSE CPUID.01h:EDX.SSE needs to be set
mov eax, 0x1 cpuid test edx, 1<<25 jz .noSSE ;SSE is available
Adding support
In order to allow SSE instructions to be executed without generating a #UD, we need to alter the CR0 and CR4 registers.
clear the CR0.EM bit (bit 2) set the CR0.MP bit (bit 1) set the CR4.OSFXSR bit (bit 9) set the CR4.OSXMMEXCPT bit (bit 10)
Here is an asm example:
;now enable SSE and the like mov eax, cr0 and ax, 0xFFFB ;clear coprocessor emulation CR0.EM or ax, 0x2 ;set coprocessor monitoring CR0.MP mov cr0, eax mov eax, cr4 or ax, 3 << 9 ;set CR4.OSFXSR and CR4.OSXMMEXCPT at the same time mov cr4, eax ret
FXSAVE and FXRSTOR
FXSAVE and FXRSTOR are used to save and load the complete SSE, x87 FPU, and MMX states from memory. The host needs to allocate 512 bytes for the storage and use that memory pointer as an operand to either FXSAVE or FXRSTOR. Before using either of those instructions, make sure to check the CPUID features for the FXSR bit. Also, like most SSE instructions, the memory operand needs to be 16-byte aligned or a #GP exception will occur. Remember to execute FXSAVE *before* any MXCSR modifications happen, or else it the register will most likely get overwritten or set to 0 based on the unknown state of the MXCSR_MASK.
Example usage:
char fxsave_region512 __attribute__((aligned(16)));
asm volatile(" fxsave %0 "::"m"(fxsave_region));
or in asm:
segment .code SaveFloats fxsave SavedFloats segment .data align 16 SavedFloats TIMES 512 db
Pitfalls: only one level of saving supported.
MXCSR and its helpers LDMXCSR and STMXCSR
The MXCSR register holds all of the masking and flag information for use with SSE floating-point operations. Just like the x87 FPU control word, if you would like to mask certain exceptions from occuring or would like to specify rounding types, MXCSR will need to be modified. Bits 16-31 are reserved and will cause a #GP exception if set. LDMXCSR and STMXCSR load and write the MXCSR register respectively. They both require a 32-bit memory operand. SSE support needs to already be set up before using either of these instructions (CR4.OSFXSR = 1, CR0.EM = 0, and CR0.TS = 0). If bits 7-12 are set, all SSE floating-point exceptions are masked. Bits 0-5 are exception status flags that are set if the corresponding exception has occured. Bits 13-14 are the RC (Rounding Control) bits. RC:0 = to nearest, RC:1 = down, RC:2 = up, RC:3 = truncate.
Время для новых букв
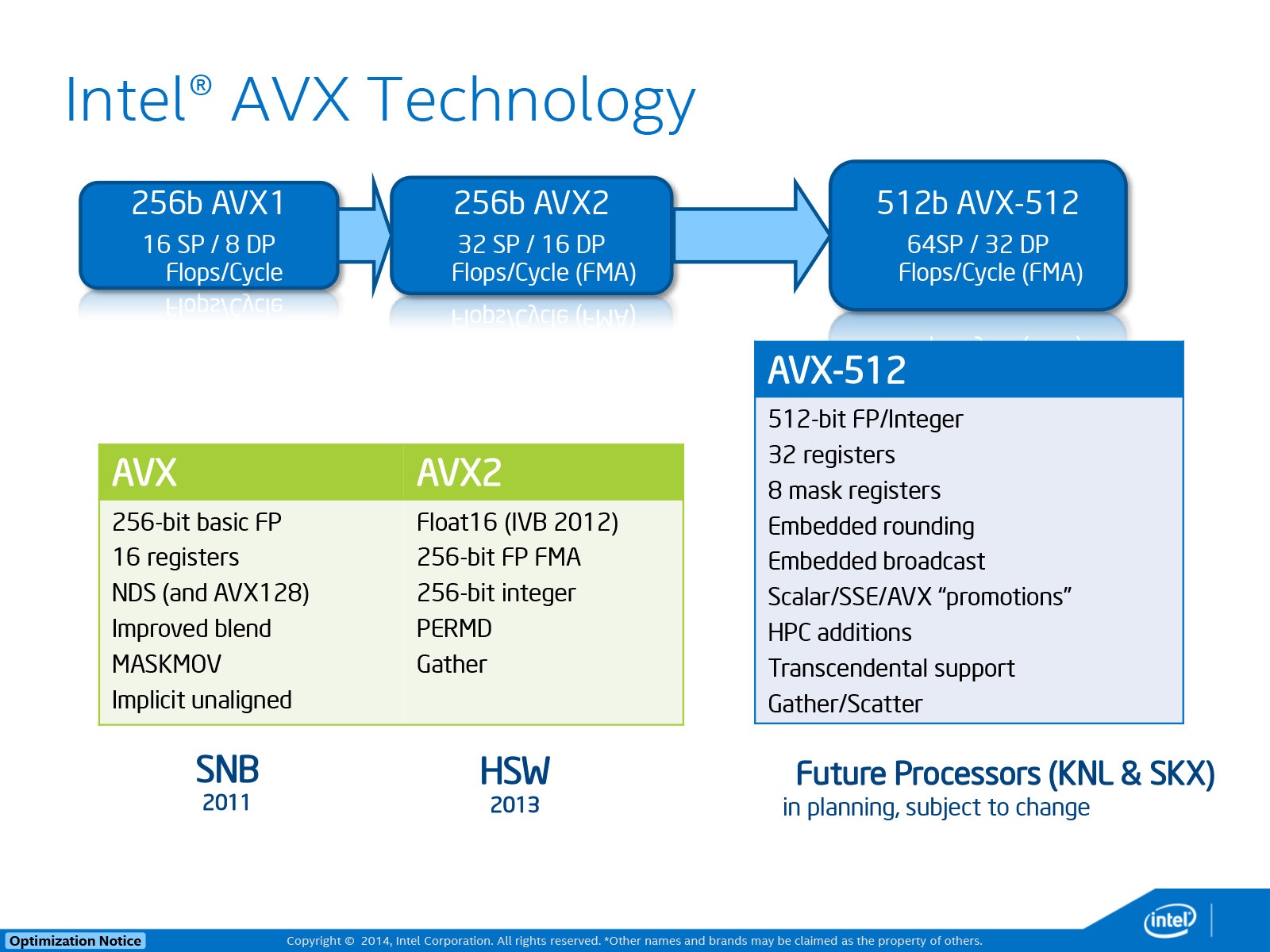
2008 год также был годом, когда Intel объявила о том, что они работают над значительным апгрейдом своей системы SIMD, и в 2011 году выкатила линейку процессоров Sandy Bridge с поддержкой набора инструкций AVX (Advanced Vector Extensions, «продвинутые векторные расширения»).
Всё удвоилось: вдвое больше векторных регистров и вдвое больше их размер.
Шестнадцать 256-битных регистров вмещают только восемь 32-битных или четыре 64-битных вещественных числа, поэтому в плане форматов данных, этот набор инструкций более ограничен в сравнении с SSE, но ведь и SSE никто не отменял. К тому времени программная поддержка векторных операций для CPU была уже хорошо отлажена, начиная с фундаментального мира компиляторов, заканчивая сложными приложениями.
И не даром: Core i7-2600K (или подобный ему), работающий на частоте 3,8ГГц, потенциально может выдавать более 230 GFLOPS (миллиардов операций с плавающей точкой в секунду) при выполнении инструкций AVX – неплохо для дополнения, относительно немного места занимающего на кристалле процессора.
Или могло бы быть неплохо, если бы он действительно работал на частоте 3,8ГГц. Частично проблема AVX заключалась в том, что нагрузка на чип получалась настолько высокой, что Intel пришлось заставить процессор автоматически снижать тактовую частоту в этом режиме примерно на 20%, чтобы уменьшить энергопотребление и не допустить перегрева. К сожалению, такова цена за выполнение любой работы SIMD в современном процессоре.
Еще одно усовершенствование, предлагаемое в AVX – это возможность работать одновременно с тремя значениями. Во всех версиях SSE операции выполнялись между двумя значениями, после чего результат заменял одно из них в регистре. При выполнении инструкций SIMD AVX не трогает исходные значения, сохраняя результирующее значение в отдельный регистр.
AVX2 был выпущен вместе с архитектурой Haswell для процессоров Core 4-го поколения в 2013 году, и представлял собой довольно значительный апгрейд, благодаря добавлению нового расширения: FMA (Fused Multiply-Add, «умножение-сложение с однократным округлением»).
Эта независимая функция в составе AVX2 была крайне востребована для приложений, работающих с векторной и матричной математикой, поскольку давала возможность выполнять две операции с помощью одной инструкции. Функция поддерживала и скалярные операции также.
Проблема оказалась в том, что FMA от Intel отличался от аналогичного расширения AMD настолько, что они были совершенно несовместимы. Причина в том, что Intel FMA представляет собой систему с тремя операндами, то есть работает с тремя отдельными значениями: два слагаемых и сумма, либо три слагаемых и сумма, замещающая одно из слагаемых.
У версии от AMD четыре операнда, поэтому она может вычислить 3 числа и записать ответ в отдельный регистр, не трогая исходные значения. Математически FMA4 лучше, чем FMA3, но его реализация немного сложнее, как с точки зрения программирования, так и с точки зрения интеграции функции в процессор.
AMD E2-9000
AMD E2-9000 — 2-ядерный процессор с тактовой частотой 1800 MHz и кэшем 2-го уровня 1024 KB. Процессор предназначен для мобильных компьютеров, разъем — Socket FP4. Имеет встроенный контроллер оперативной памяти (1 канала, DDR4-1866) и контроллер PCI Express 3.0 (количество линий — 8).
| Основная информация: | |
| Год выхода | 2016 |
| Сегмент | для мобильных компьютеров |
| Socket | Socket FP4 |
| Количество ядер | 2 |
| Количество потоков | 2 |
| Базовая частота | 1800 MHz |
| Turbo Core | 2200 MHz |
| Разблокированный множитель | нет |
| Архитектура (ядро) | Stoney Ridge |
| Техпроцесс | 28 nm |
| Транзисторов, млн | 1200 |
| TDP | 10 W |
| Макс. температура | 90° C |
| Официальные спецификации | перейти > |
| Внутренняя память | |
| Кэш L1, КБ | 96 + 2×32 |
| Кэш L2, КБ | 1024 |
| Кэш L3, КБ | нет |
| Встроенные модули | |
| Графический процессор | Radeon R2 series600 MHz, 128 shaders |
| Контроллер оперативной памяти | 1-канальный(DDR4-1866) |
| Контроллер PCIe | PCI Express 3.0 (8 линий) |
| Другие модули / периферия | • Secure processor• Унифицированный видеодекодер (UVD)• Модуль кодирования видео (VCE) |
| Инструкции, технологии | |
| • MMX• SSE• SSE2• SSE3• SSSE3• SSE4 (SSE4.1 + SSE4.2)• SSE4A• AES (Advanced Encryption Standard)• AVX (Advanced Vector Extensions)• AVX 2 (Advanced Vector Extensions)• BMI1 (Bit Manipulation inst. 1) | • F16C (16-bit Floating-Point conversion)• FMA3 (3-operand Fused Multiply-Add)• FMA4 (4-operand Fused Multiply-Add)• TBM (Trailing Bit Manipulation)• XOP (eXtended Operations)• AMD64• EVP (Enhanced Virus Protection)• AMD-V (AMD Virtualization)• Turbo Core• PowerNow! |
www.chaynikam.info
- Программа показывающая температуру процессора и видеокарты в игре
- Процессоры интел и амд сравнение
- Разгон процессора msi
- Как проверить производительность процессора
- Как проверить загрузку процессора
- Какой процессор лучше i3 или i5
- Без термопасты процессор
- Чем заменить термопасту для процессора
-
Какая нормальная температура у процессора
-
Как на виндовс 10 посмотреть температуру процессора
- Как разогнать центральный процессор
Изменения
Добавлены инструкции, ускоряющие компенсацию движения в видеокодеках, быстрое чтение из WC памяти, множество инструкций для упрощения векторизации программ компиляторами. Кроме того, в SSE4.2 добавлены инструкции обработки строк 8/16 битных символов, вычисления CRC32, popcnt. Впервые в SSE4 регистр xmm0 стал использоваться как неявный аргумент для некоторых инструкций.
Смешивания
BLENDV xmm1, xmm2/m128, — (Variable Blend Packed Single/Double Precision Floating-Point Values)
Выбор каждого 32/64-битного поля результата осуществляется в зависимости от знака такого же поля в неявном аргументе xmm0: либо из первого, либо из второго аргумента.
BLEND xmm1, xmm2/m128, imm8 — (Blend Packed Single/Double Precision Floating-Point Values)
Битовая маска (4 или 2 бита) в imm8 указывает из какого аргумента следует взять каждое 32/64-битное поле результата.
PBLENDVB xmm1, xmm2/m128, — (Variable Blend Packed Bytes)
Выбор каждого байтового поля результата осуществляется в зависимости от знака байта такого же поля в неявном аргументе xmm0: либо из первого, либо из второго аргумента.
PBLENDW xmm1, xmm2/m128, imm8 — (Blend Packed Words)
Битовая маска (8 бит) в imm8 указывает из какого аргумента следует взять каждое 16-битное поле результата.
Выбор подходящего расширения команд
Первые SIMD-инструкции появились в процессоре Intel Pentium MMX. Собственно MMX — это и есть название расширения команд. Этот набор был настолько важным, что Intel вынесла его в название процессора. С помощью MMX я когда-то давно писал простенькие алгоритмы вроде смешивания двух изображений или суперсемплинга. Писал на Дельфи, но чтобы использовать MMX, приходилось спускаться на уровень ниже и делать вставки на ассемблере.
С тех пор я не слишком следил за развитием процессорных команд и связанных с ними средств разработки. Поэтому, когда я недавно снова взялся за SIMD, был приятно удивлен. Нет, компилятор все еще не способен автоматически применять SIMD-инструкции в более-менее сложных случаях. А если и способен, то обычно у него получается хуже, чем самостоятельно написанный SIMD-код. Но зато для применения SIMD уже давно не нужно писать на ассемблере, все делается специальными функциями — интринсиками.
Чаще всего каждому интринсику соответствует одна конкретная инструкция процессора. Т.е. написанный код получается очень эффективный и близкий к железу. Но при этом для написания кода вы пользуетесь знакомым и относительно безопасным синтаксисом Си. Вы как обычно подключаете заголовочный файл, в котором определены функции-интринсики, как обычно объявляете переменные, используя специальные типы данных, и как обычно вызываете функции. Словом, пишите обычный код. Небольшое неудобство только в том, что с SIMD-типами данных нельзя использовать математические операции, для всех вычислений нужно использовать интринсики. Грубо говоря, нельзя написать + , можно только (название функции выдумано).
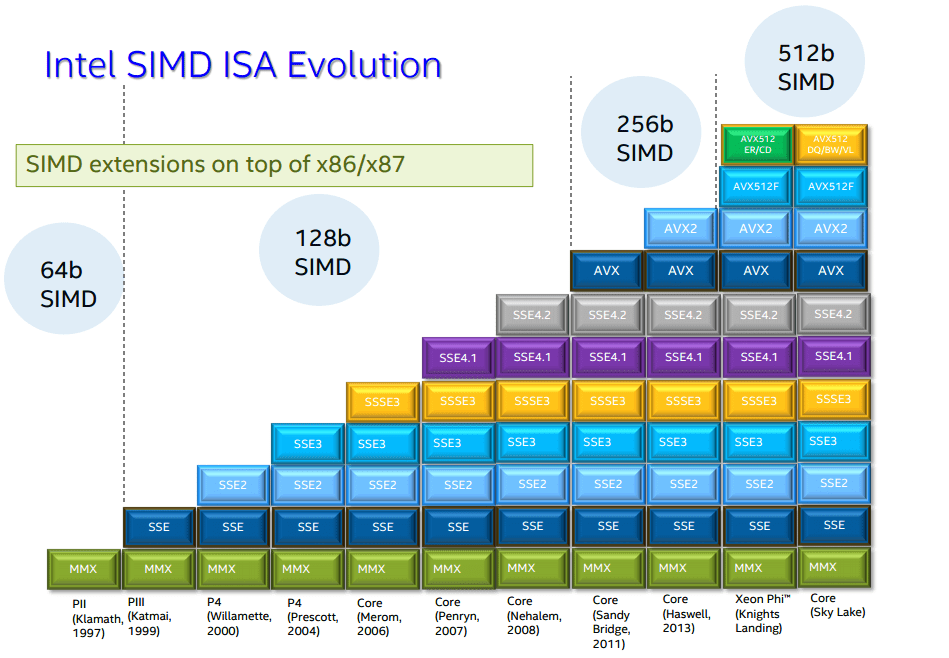
SIMD-расширений много. В основном наличие в процессоре более нового расширения означает наличие всех предшественников. По хронологии появления расширения располагаются в следующем порядке:
MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, AVX-512
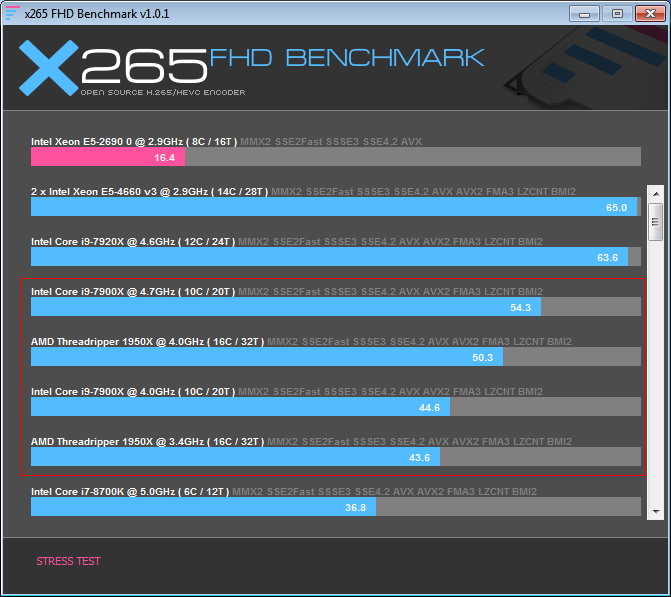
Как видите, список внушительный. Не на каждой машине есть каждое расширение. Найти живой x86 процессор без MMX можно разве что в музее. SSE2 — обязательное расширение для 64-битных процессоров, т.е. в наши дни тоже есть практически везде. Поддержку SSE4.2 можно найти в любом процессоре, начиная с архитектуры Nehalem, т.е. с 2008 года. А вот AVX2 есть только у не бюджетных процессоров Intel, начиная с ядра Haswell, т.е. с 2013 года, а у AMD они появились в процессорах Ryzen, выпущенных в 2017 году. AVX-512 пока доступны только в серверных процессорах Intel Xeon и Xeon Phi.
От выбора набора инструкций, зависит производительность и сложность написания кода, а также поддержка процессоров. Иногда разработчики делают несколько реализаций своего кода под разные наборы инструкций. Я выбрал два: SSE4.2 и AVX2. Я рассуждал так: SSE4.2 — базовый набор, который должен быть у всех, кого хоть сколько волнует производительность и не стоит мучаться, реализовывая все, например, на SSE2. А AVX2 для тех, кто не ленится менять железо хотя бы раз в 3 года. Что бы вы не выбрали для своей реализации, со временем ваш выбор будет становиться только более верным, потому что количество процессоров на рынке с выбранным набором инструкций будет только увеличиваться.
2022
2022
, сентябрь
Отказ компании Intel от наименования своих процессоров — Pentium и Celeron >>>
ID материала: 13646
/ Просмотров: 327
/ вычислительная техника / центральный процессор
Компания Intel отказалась от именования своих процессоров названиями Intel и Celeron. Название Pentium впервые появилось в 1993 году с появлением процессоров новой (суперскалярной) архитектуры, позволяющей обрабатывать две операции за один такт. Такие процессоры предполагалось назвать 80586 (по аналогии с 80486, 80386, 80286).
Бренд Celeron впервые появился с дебютом новых экономичных процессоров на архитектуре Covington, на которой также были основаны процессоры Intel Pentium II. Celeron отличался от последнего…
2022
, август
Потребительские процессоры AMD на архитектуре Zen 4 >>>
ID материала: 13623
/ Просмотров: 314
/ вычислительная техника / центральный процессор
AMD представила потребительские процессоры для массового сегмента новой архитектуры — Zen 4.
5-нанометровый технологический процесс. По сравнению с процессорами на архитектуре Zen 3 улучшен показатель IPC до 13%. Также значительно увеличены тактовые частоты: базовая до 4,5 — 4,7 ГГц, в турбобусте — до 5,3 — 5,7 ГГц. Увеличен объем L2-кеша до 1 Мб на ядро, в 1,5 раза расширен кеш микроопераций. Добавлена поддержка инструкций AVX-512 (VNNI). В связи с этим возрос TDP до 170 Вт. Количество ядер — до 16 в старшей…
Какие процессоры поддерживают SSE 4.1 и SSE 4.2
Пользователи некоторых старых компьютеров все чаще обнаруживают, что часть новых программ и компьютерных игр больше не работает на их системах. При чем это не зависит от версии или разрядности операционной системы. Ограничения находятся на аппаратном уровне и связаны с поддержкой инструкций SSE 4.1 и SSE 4.2. В данной статье мы расскажем, что это такое и какие процессоры поддерживают SSE 4.1 и SSE 4.2.
Что такое SSE 4.1 и SSE 4.2
SSE 4 – это набор инструкций, который применяется в процессорах Intel и AMD. Впервые о данном наборе инструкций стало известно в конце 2006 года на форуме для разработчиков Intel, а первые процессоры с его поддержкой появились в 2008 году.
Набор SSE 4 включает в себя 54 новых инструкций, 47 из которых относятся SSE 4.1 и еще 7 к SSE 4.2. Данные инструкции включают в себя улучшенные целочисленные операции, операции с плавающей точкой, операции с плавающей точкой одинарной точности, упаковочные операции DWORD и QWORD, быстрые регистровые операции, операции для работы с памятью, а также операции со строками.
Использование данных новых инструкций позволяет значительно повысить производительность программ. Например, такие программы DivX 6.7 и VirtualDub 1.7.2 показывают рост производительности на 49%, а TMPGEncoder Xpress 4.4 на 42%.
В связи с ростом производительности, наборы SSE 4.1 и SSE 4.2 уже давно активно используются разработчиками программ и компьютерных игр. Естественно, если программа требует данного набора инструкций, то без него работать она не будет.
В результате многие современные игры и программы отказываются запускаться на старых компьютерах. Например, наличия SSE 4.1 или 4.2 требуют такие игры как No Man Sky, Dishonored 2, Far Cry 5 или Mafia 3. В некоторых случаях, эту проблему можно решить с помощью программного эмулятора, но это приводит к значительному снижению производительности.
Процессоры, поддерживающие SSE 4.1 и SSE 4.2
Практически все современные процессоры поддерживают инструкции SSE 4.1 и SSE 4.2. В настольных процессорах Intel поддержка SSE 4.1 появилась в архитектуре Penryn (процессоры Core 2 Duo, Core 2 Quad), а поддержка SSE 4.2 в архитектуре Nehalem (процессоры Intel Core 1-поколения). Полная же поддержка инструкций SSE 4.2 (включая POPCNT и LZCNT) доступна начиная с архитектуры Haswell (процессоры Intel Core 4-поколения). Более подробная информация о поддержке в таблице внизу.
| Микроархитектура Intel | Поддержка инструкций |
| SilvermontGoldmontGoldmont PlusTremont | SSE 4.1 и SSE 4.2 (включая POPCNT) |
| Penryn | SSE 4.1 |
| Nehalem | SSE 4.1 и SSE 4.2 (включая POPCNT) |
| Haswell и новее | SSE 4.1 и SSE 4.2 (включая POPCNT и LZCNT) |
В настольных процессорах AMD сначала появилась поддержка собственного набора инструкций SSE4a, который отсутствовал в процессорах Intel. Но, уже начиная микроархитектуры Bulldozer (FX) была внедрена поддержка SSE 4.1 и SSE 4.2 (включая инструкции POPCNT и LZCNT). Последовавшая в дальнейшем микроархитектура Zen (Ryzen) также в полной мере поддерживает SSE 4.1 и SSE 4.2. Более подробная информация о поддержке в таблице внизу.
| Микроархитектура AMD | Поддержка инструкций |
| K10BobcatJaguarPuma | SSE 4a (включая POPCNT и LZCNT) |
| BulldozerPiledriverSteamrollerExcavatorZenZen+Zen2 | SSE 4a, SSE 4.1, SSE 4.2 (включая POPCNT и LZCNT) |
Как узнать, что процессор поддерживает SSE 4.1 и SSE 4.2
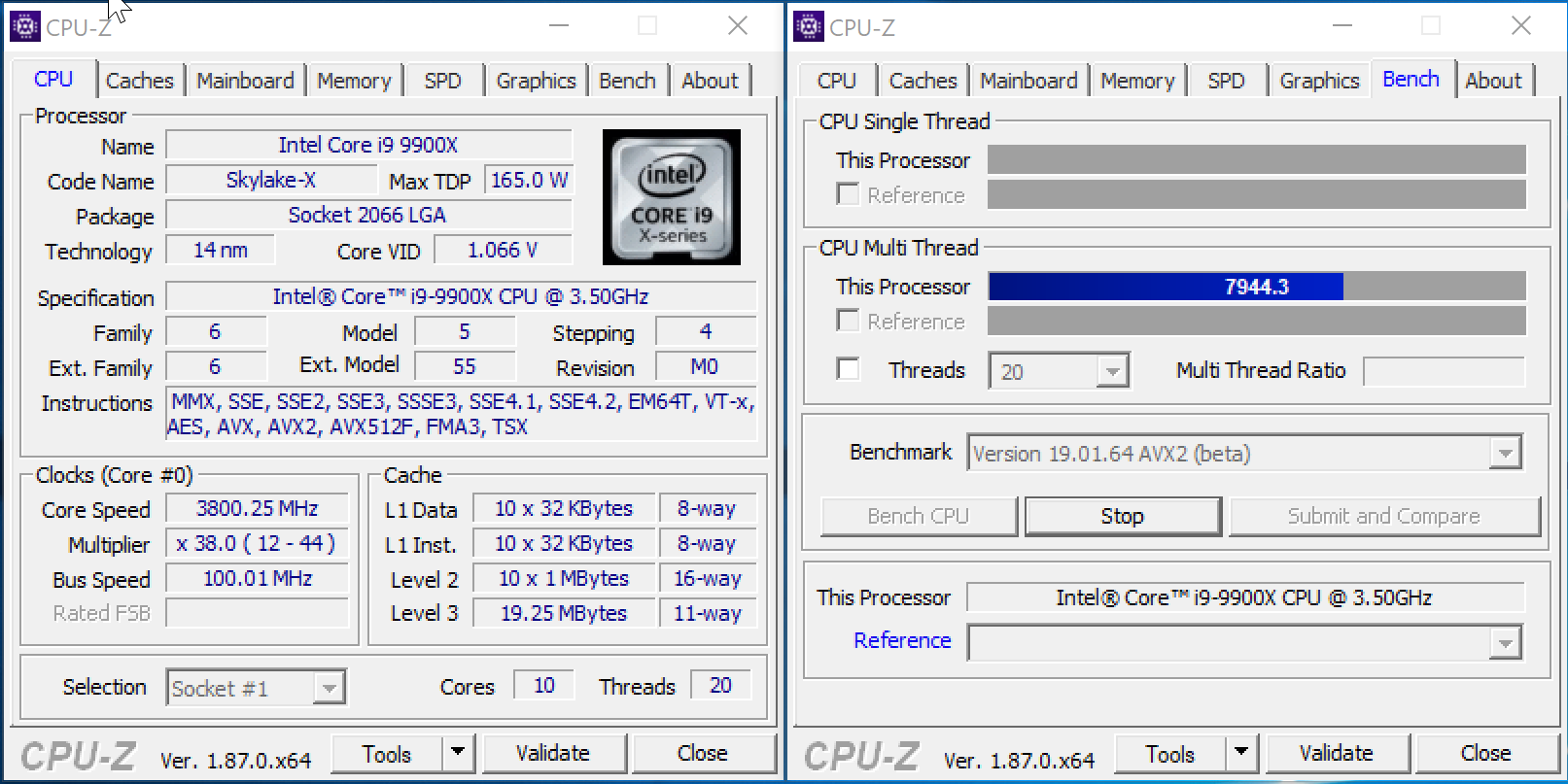
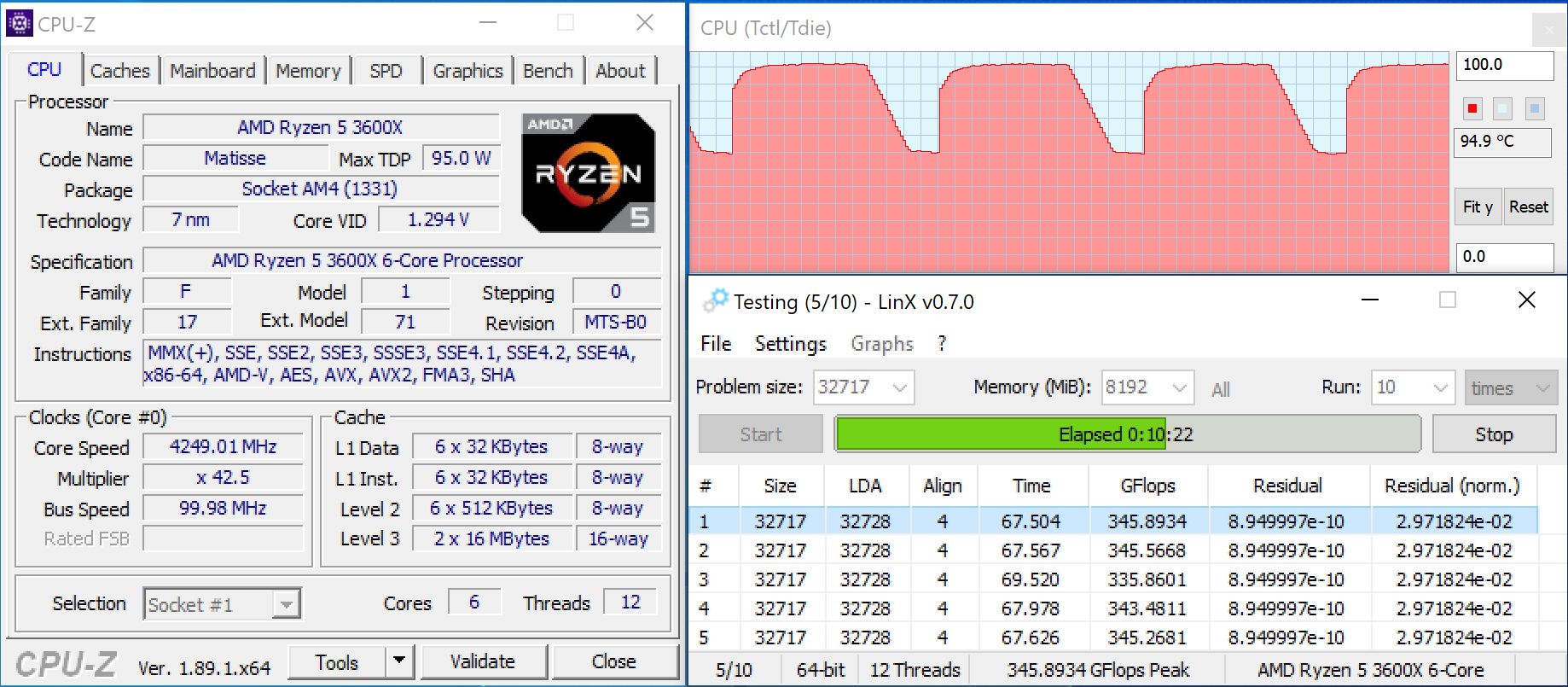
Если у вас уже есть готовый компьютер и вы хотите узнать, поддерживает ли его процессор инструкции SSE 4.1 и SSE 4.2, то это можно сделать, просто запустив программу CPU-Z. Данная программа предназначена для сбора информации об установленном процессоре. С ее помощью можно узнать название процессора, а также все его основные характеристики. Скачать CPU-Z можно с официального сайта.
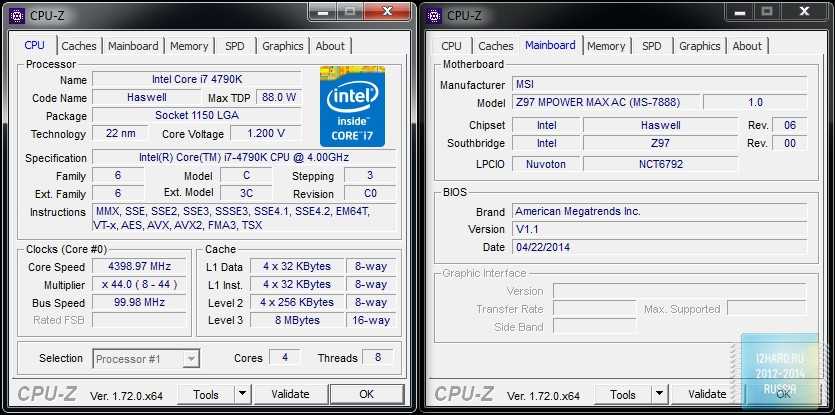
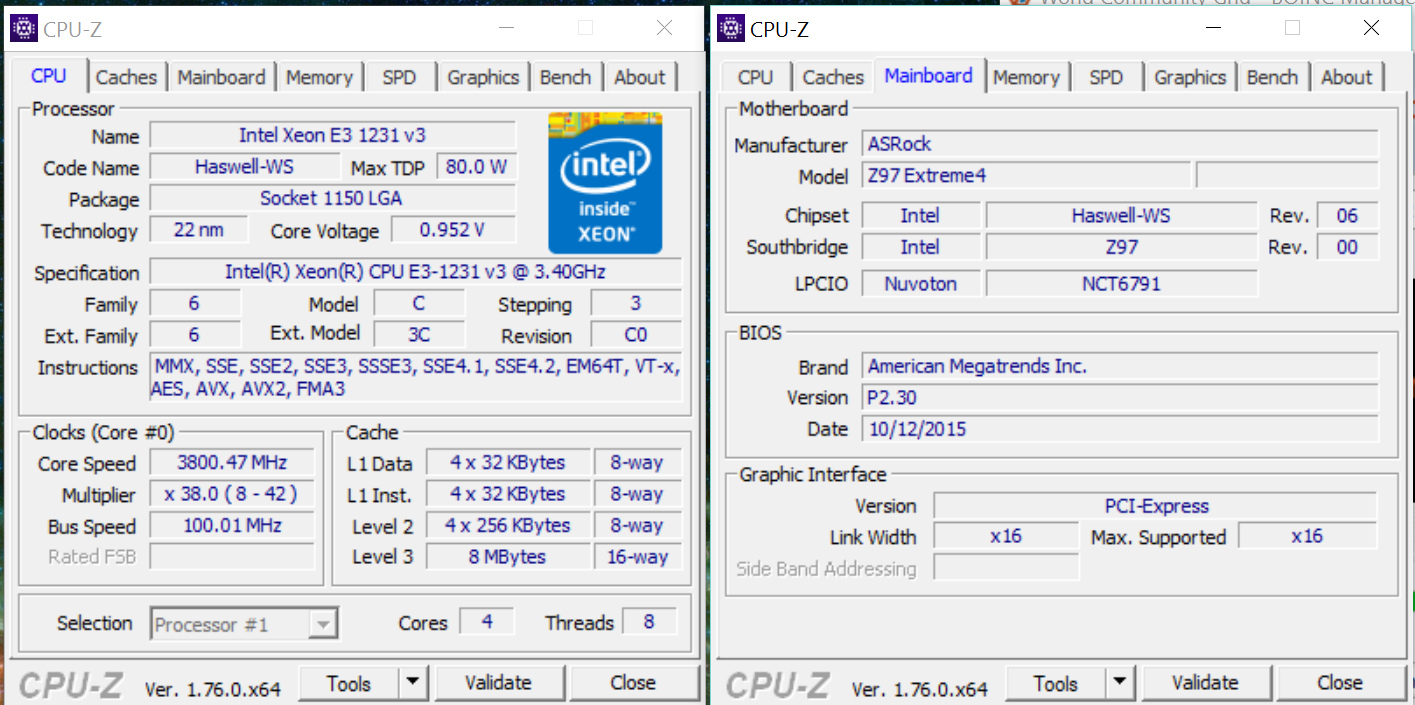
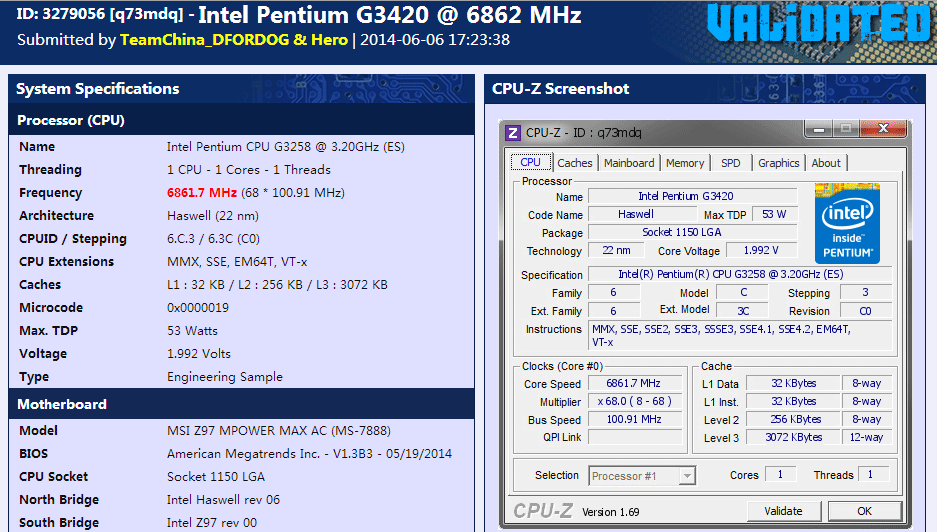
Среди прочего, с помощью CPU-Z можно проверить наличие поддержки инструкций SSE 4.1 и SSE 4.2. Для этого нужно просто запустить CPU-Z и изучить строку «Instructions» на вкладке «CPU».
Если процессора на руках пока нет, то можно просто поискать скриншот CPU-Z в любой поисковой системе, например, в Google. Для этого нужно ввести поисковый запрос «cpu-z название процессора» и перейти к просмотру картинок.
Таким образом можно найти информацию практически о любом современном процессоре.
Что такое SSE2?
SSE2 являются SIMD — эта аббревиатура с английского языка переводится, как единая инструкция и множество данных. SIMD — это своего рода поток команд, который реализует параллелизм при работе с данными. Без них компьютеры нового поколения не смогли бы выполнять одновременно сотни процессов.
Набор был разработан инженерами компании Intel. Главная его цель — расширить возможности процессоров.
Без них компьютер лишается следующих возможностей:
- SSE2 содержит команды по управлению кэшем, которые минимизируют заполнение памяти данными, тщательно сортируют их;
- Сложные формулы для вычисления и преобразования чисел;
- Инструкции для вычисления скалярных данных и для работы с упакованными данными;
- Содержит набор инструкций для работы с потоковыми данными. Использует новые методы вычислений, которые эффективнее инструкций MMX;
- SSE2 дополнила прошлую первую версию инструкций, добавив 144 новых команд;
- И многое другое.
SIMD представляет собой процессор, который часто называют контроллером. Практически во всех случаях он является главным и содержит дополнительные модули, в которых происходит обработка данных или числовые вычисления. Сам процессор ничего не вычисляет, он лишь даёт указания своим подопечным, чем им необходимо заниматься в данный момент. То есть играет роль аналитика и управляющего.
В свою очередь каждый управляемый модуль имеет собственную память. Когда основной процессор получает команду к вычислению, он переправляет её всем вычислительным элементам. После чего каждый свободный элемент принимается за работу. Подобную архитектуру используют в создании компьютерных процессоров не только Intel, но и AMD.
И дальше что?
Много лет назад процессор с возможностью обработки векторной математики ознаменовал собой эпохальный прорыв. Современные процессоры обладают огромными возможностями, предлагая множество наборов инструкций для обработки целочисленных операций и операций с плавающей запятой для скалярных, векторных и матричных данных.
Что касается последних двух типов данных, то CPU теперь напрямую конкурируют с GPU: ведь мир 3D-графики – это как раз всё, что связано с SIMD, векторами, плавающими точками и т.д. И производители GPU не спали – разработка графических ускорителей велась стремительными темпами. В начале 2010-х годов купить видеокарту, процессор которой способен выполнять почти 800 миллиардов инструкций SIMD в секунду, вы уже могли менее чем за 500 долларов.
Это больше, чем то, на что сейчас способны лучшие из десктопных CPU. Но они и не предназначены для рекордов в какой-то конкретной области – их задача обрабатывать очень обобщенный код, который зачастую не повторяется или легко распараллеливается. Поэтому, не стоит думать, что возможности SIMD столь жизненно-важны для CPU, скорее это полезное дополнение к его арсеналу.
Вас интересует производительность SIMD в чистом виде? Ваш выбор – видеокарта, а не материнка!
Стремительное развитие графических процессоров недвусмысленно намекает, что для CPU нет нужды иметь чересчур большие векторные блоки, и почти наверняка именно поэтому AMD даже не пыталась разрабатывать своего собственного преемника для AVX2 (расширение, которое они используют в своих чипах с 2015 года). Давайте также не будем забывать, что процессоры следующего поколения могут больше походить на мобильные однокристальные (SoC, System-on-a-Chip), где под каждый тип задач выделена площадь на кристалле. Intel, в свою очередь, похоже, стремится внедрить AVX-512 в как можно большее количество продуктов.
Ждёт ли нас ещё и AVX-1024? Вряд ли, либо очень нескоро. Скорее всего, Intel займётся расширением AVX-512 с помощью дополнительных компонентов с инструкциями, чтобы повысить гибкость, а чистую SIMD-производительность переложит на плечи своей недавно разработанной линейки графических процессоров Xe.
Библиотеки SSE и AVX теперь являются неотъемлемой частью программного обеспечения: Adobe Photoshop требует, чтобы процессоры поддерживали как минимум SSE4.2; API машинного обучения TensorFlow требует поддержки AVX; Microsoft Teams может выполнять фоновые видеоэффекты, только если доступен AVX2.
Это говорит только об одном: несмотря на то, что в плане обработки SIMD графическим процессорам нет равных, этот функционал ещё долго будет в арсенале CPU. Так что будем ждать нового поколения векторных расширений и надеюсь, реклама нас впечатлит.
Выводы
В этой статье мы довольно подробно рассказали о поддержке процессорами инструкций AVX, AVX2, а также показали несколько способов, позволяющих выяснить наличие такой поддержки конкретно вашим процессором. Надеемся, что дополнительная информация об используемом процессоре будет полезна для вас, а также поможет в выборе процессора в будущем.
В предыдущей заметке, мы рассматривали способ запуска Photoshop на устройствах, где процессоры не поддерживают SSE 4.2. Способ не универсальный и на данный момент, на самых последних версиях Photoshop, данный метод уже блокируется со стороны Adobe, начиная с версии Photoshop 22.3 и выше. При этом, возникает логичный вопрос, а как вообще узнать, поддерживает ли конкретный процессор SSE 4.2?