
Как использовать контрольную сумму в Windows
Существует множество инструментов и утилит для проверки контрольных сумм в Windows, но мы будем использовать встроенные инструменты, которые поставляются с Windows 7, Windows 8 и Windows 10.
Начните с загрузки файла, который вы хотите проверить, как обычно. Помните, что если это сжатый (заархивированный) файл, вы должны запустить контрольную сумму для сжатой папки перед извлечением содержимого.
Веб-сайт VLC позволяет просто щелкнуть ссылку, чтобы просмотреть контрольную сумму прямо на странице загрузки. Другие поставщики программного обеспечения могут потребовать, чтобы вы загрузили контрольную сумму в текстовом файле, и в этом случае вы можете открыть ее с помощью Блокнота или аналогичного текстового редактора..
Контрольная сумма представляет собой длинную строку, казалось бы, случайных чисел и букв. Как только вы увидите это, выполните следующие действия:
- открыто Командная строка удерживая Ключ Windows и нажав ‘Р’. Тип «CMD”В текстовое поле и нажмите Войти.
- Перейдите в папку, где находится ваш файл. Если вы используете настройки по умолчанию, эта команда должна работать: CD Загрузки
- Введите следующую команду, заменив файлом, который вы хотите проверить, включая его расширение, и алгоритмом хеширования, указанным поставщиком программного обеспечения. В этом случае страница загрузки VLC сообщает, что алгоритм хэширования — SHA256.certutil -hashfile
- Нажмите Войти генерировать контрольную сумму. Сравните контрольную сумму от поставщика программного обеспечения с той, которую вы только что создали.
Если две контрольные суммы совпадают, вы можете идти. Файл не был поврежден или изменен по сравнению с оригинальной версией.
Если контрольные суммы не совпадают, возникла проблема. Возможно, он не загружен должным образом, или хакер мог похитить ваше соединение, чтобы заставить вас загрузить поврежденный файл с вредоносного сервера. Модифицированная версия может содержать вредоносное ПО или другие недостатки. Мы не рекомендуем устанавливать программное обеспечение, которое не имеет проверенной контрольной суммы..
Команда certutil в Windows может использовать следующие алгоритмы хеширования для генерации контрольной суммы:
- MD2
- MD4
- MD5
- SHA1
- SHA256
- SHA384
- SHA512
Пишем все остальное
Имея в наличии все необходимые базовые преобразования, определенные стандартом, можно приступить непосредственно к реализации алгоритма «Стрибог» в целом.
Для начала определим структуру, в которую будем складывать все исходные, промежуточные и конечные результаты вычислений:
Далее напишем преобразование E, которое является частью функции сжатия. В этом преобразовании задействовано двенадцать так называемых итерационных констант (C1 — C12), на основе которых вычисляются раундовые ключи K. Для вычисления этих раундовых ключей определим функцию , которая представляет собой сочетание преобразований S, P и L, а также побайтного сложения по модулю 2:
Для этой функции необходимо описать итерационные константы, которых, как мы уже говорили, двенадцать штук (для краткости здесь эти константы показаны не в полном объеме):
Если ты попытаешься сравнить приведенные выше константы с текстом стандарта, то увидишь, что эти самые константы записаны «задом наперед». Дело в том, что все байтовые массивы (в том числе и строки тестовых примеров) в тексте стандарта описаны таким образом, что нулевой их элемент находится в конце массива, а не в начале, как мы привыкли, поэтому строки перед использованием надо «переворачивать».
Далее пишем саму функцию преобразования E:
И, используя эти функции, пишем самую главную функцию алгоритма «Стрибог» — функцию сжатия g:
Схема функции сжатия g
В самом начале мы говорили, что хеширование выполняется блоками по 64 байта, а последний блок, если он меньше 64 байт, дополняется нулями с одной единичкой. Для этой операции вполне подойдет функция :
Теперь открываем руководящий документ на шестой странице и внимательно разбираемся с этапами вычисления столь нужной нам хеш-функции.
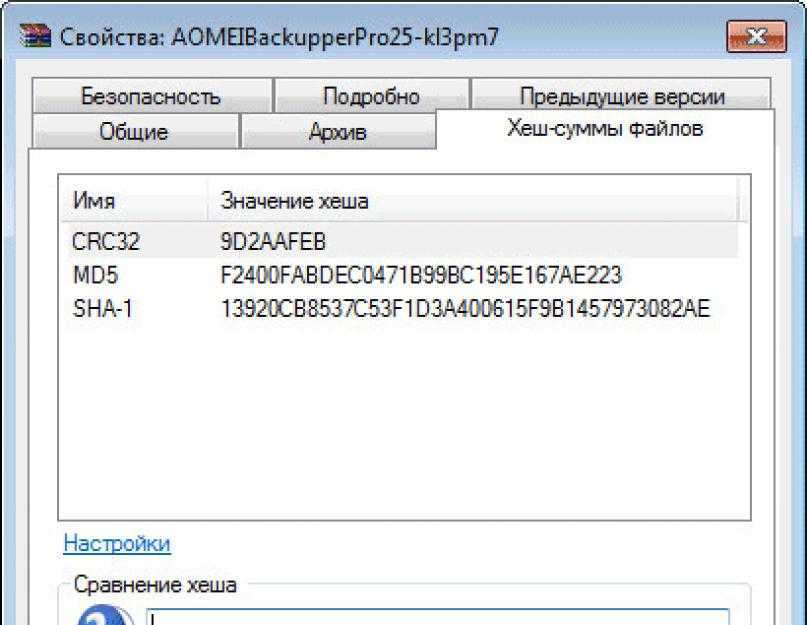
Как узнать хэш файла при помощи утилиты HashTab
Помимо инструментов Windows для определения контрольной суммы файла можно использовать сторонние приложения. Например, одной из удобных программ, способной определить хэш файла, является HashTab. Это крайне простое приложение, которое можно бесплатно скачать из интернета.
После загрузки программы HashTab и установки, в свойствах файлов создается новая вкладка, которая носит название “Хэш-суммы файлов”. В этом вкладке можно видеть расчет контрольной суммы для файла в различных алгоритмах.
В наш цифровой век, даже один жалкий байт может стоить много. Если в файле ISO образа недостает хотя бы байта, то польза от подобного файла будет сомнительной. В один прекрасный момент, когда вы захотите проинсталлировать себе новую операционную систему, процесс прервется на определенном этапе установки, из-за того, что образ оказался битым. Поэтому любой ISO файл следует просканировать на целостность, перед тем как прожечь его на болванку. Таким образом, вы экономите свое драгоценное время и предостерегаете себя от нелепых казусов, возникших в процессе использования дисков на которых был записан тот или иной ISO образ. И еще один важный момент, битым ISO образ может оказать как по причине, не зависящей от вас – например, сам файл был загружен автором уже битым. А также по причине нестабильности вашего интернет соединения, что в итоге привело к утрате данных при скачивании файла на ваш компьютер.
Для сканирования контрольной суммы ISO образа, вам следует последовательно выполнить следующие шаги. Подробно описывать нет смысла, так как программа довольно простая и не требует глубоких познаний и серьезного описания. Однако давайте пошагово:
- Ищем на просторах всемирной паутины программу HashTab (или ей аналогичную программу, предназначенную для проверки контрольных сумм (или хеш-сумм) ISO образов), загружаем ее себе на компьютер и инсталлируем. Скачать программу можно, например, отсюда http://www.softportal.com/get-19546-hashtab.html , либо с официального сайта. Процесс установки достаточно простой и не требует описания;
- Далее жмем правой клавишей мыши на файл ISO образа и выбираем из всплывающего контекстного меню пункт «Свойства», где будет располагаться, новая вкладка, созданная программой HashTab;
- Переходим во вкладку «Хеш-суммы файлов», там будет указана хеш-сумма скачанного файла. Эта сумма является контрольной для того файла который вы скачали и даже в случае его нецелостности, он все равно будет иметь контрольную сумму;
- Копируем хеш-сумму из описания к ISO файлу (обычно, в теме, откуда вы скачиваете файл, указывается контрольная сумма ISO образа, так же контрольная сумма должно присутствовать на обратном обороте диска, если образ скопирован с диска и если диск является лицензионным), вставляем ее в поле «Сравнение хеша» и нажимаем кнопку «Сравнить файл…».
Готово! Таким образом, мы узнаем, совпадают ли контрольные суммы, и убедимся в готовности ISO образа для прожига. Если контрольные суммы разнятся, то необходимо скачать ISO файл заново и еще раз проверить его целостность. Если окажется, что ISO образ, скачанный повторно все равно битый, то лучше вам поискать на просторах интернета другой образ и желательно от другого автора.
Самое интересно, что программа HashTab доступна как для пользователей операционной системы Windows, так и для ценителей MacOs. Поэтому HashTab является универсальным инструментом для проверки контрольных сумм ISO образов. И даже если у вас есть несколько компьютеров, на которых установлены разные операционные системы, вам будет куда привычнее использовать одно программное обеспечение, нежели искать отдельные программы, предназначенные для разных операционных систем. В интернете довольно много аналогичных решений, что позволяет вам выбрать среди обилия практически одинаковых программ, отличающихся друг от друга разве что интерфейсом. Впрочем, все эти программы довольно простые и не сильно широки в плане своей функциональности, поэтому, что бы вы ни выбрали, все это будет примерно одного поля ягода. Успехов вам и целостности информации!
Многие сталкиваются с такой проблемой. Скачал, например, файл-образ windows
, записал на диск, а при установке привод не может прочесть данные и, как итог, windows не устанавливается. К этому часто приводят ошибки при скачивании и записи образа. Как бороться? Читаем статью.
Контрольная сумма
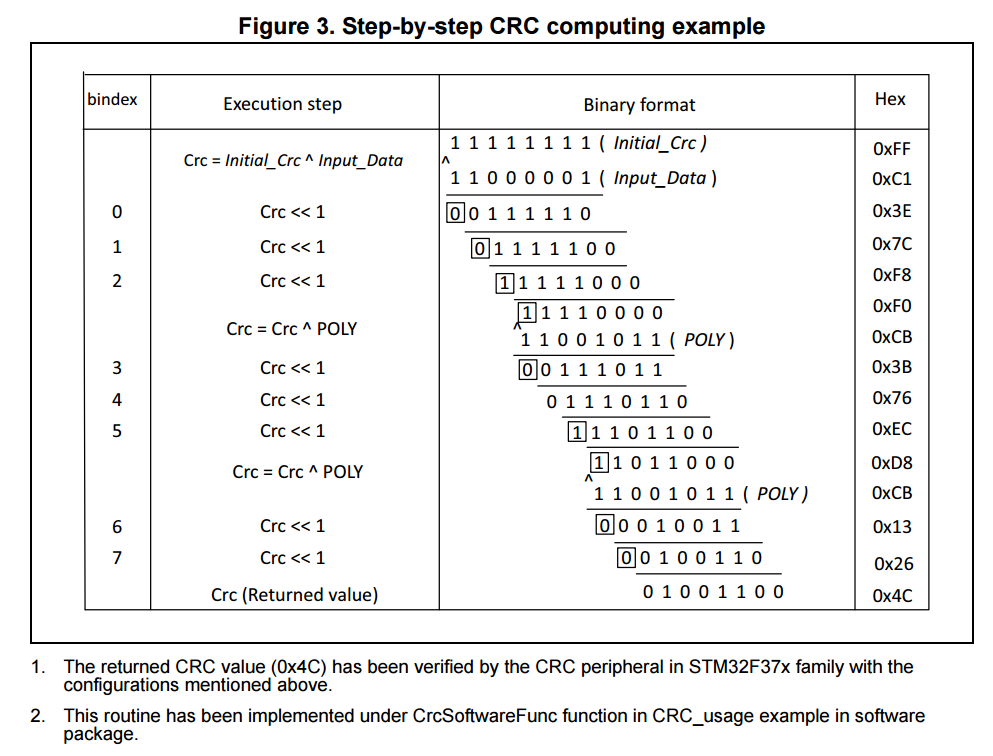
Самый простой вариант – контрольная сумма. Перед отправкой данных передатчик суммирует все байты и отправляет их например последними в посылке. Благодаря такой штуке как переполнение переменной, даже в один байт можно бесконечно суммировать данные и получить в итоге конкретное число, олицетворяющее все передаваемые данные. Например, передаём набор байтов 201, 125, 47, 94, 10, 185. Их суммой будет число 662, если брать ячейку int, или 150, если это byte. Осталось отправить контрольную сумму последним байтом (или двумя, если передаём int число)! Приёмник получает посылку, в свою очередь суммирует все байты кроме последнего (или двух последних, если контрольная сумма 16-битная), а затем сравнивает это значение с полученной контрольной суммой. Если отличается хоть на 1 – данные повреждены. Причём повреждёнными при передаче могут быть как сами данные, так и контрольная сумма: в любом случае они не совпадут, а это означает, что передача произошла с ошибкой. Давайте рассмотрим пример “передачи и приёма” структуры, где будет использоваться конструкция, позволяющая разбивать любые данные на байтовый поток. Три таких конструкции мы рассмотрели в уроке про указатели и ссылки. Структуру используем для удобства упаковки и использования данных. Универсальная для любого типа данных функция расчёта хеш-суммы может выглядеть так:
byte getHash(byte* data, int length) { byte hash = 0; int i = 0; while (length–) { hash += *(data + i); i++; } return hash;}
И возвращать байт суммы. Создадим и заполним структуру данными и прогоним через эту функцию. В последний байт структуры запишем контрольную сумму:
// структура данных посылкиstruct MyData { byte channel; int val_i; float val_f; byte hash; // байт контрольной суммы};void setup() { Serial.begin(9600); // создаём и заполняем дату MyData data; data.channel = 16; data.val_i = 12345; data.val_f = 3.1415; data.hash = 0; // расчёт суммы byte thisHash = getHash((byte*)&data, sizeof(data)); // пакуем в посылку data.hash = thisHash; // выведем для отладки Serial.println(thisHash); // выдаст 102}
Теперь можно передать структуру приёмнику! Пример “синтетический”, так как кому и каким способом передавать данные мы не рассматриваем. Хотя, можно отправить по Serial, например с одной Ардуины на другую, как в уроке по парсингу Serial:
Serial.write((byte*)&data, sizeof(data));
Далее на приёмнике примем данные:
// структура данных посылкиstruct MyData { byte channel; int val_i; float val_f; byte hash; // байт контрольной суммы};MyData rxData;void setup() { Serial.begin(9600);}void loop() { if (Serial.readBytes((byte*)&rxData, sizeof(rxData))) { // приняли данные }}




Теперь нужно убедиться в том, что данные верны. Для этого прогоним их через ту же суммирующую функцию, но без учёта последнего байта, так как он сам является суммой:
byte thisHash = getHash((byte*)&rxData, sizeof(rxData) – 1);
Если значение совпадёт с переданным rxData.hash – данные верны! Дополним предыдущий код:
void loop() { if (Serial.readBytes((byte*)&rxData, sizeof(rxData))) { // читаем дату byte thisHash = getHash((byte*)&rxData, sizeof(rxData) – 1); // считаем сумму if (thisHash == rxData.hash) { // данные верны } else { // данные повреждены } }}
И по условию можем выполнять какие-то действия, например применить полученные данные к устройству или проигнорировать их. Достоинства контрольной суммы:
- Быстрое и простое вычисление на любой платформе
- Возможность сделать 8 и 16 бит без особых вмешательств в код (это ваше домашнее задание)
Недостатки контрольной суммы:
Низкая надёжность по сравнению с другими алгоритмами
Низкая надёжность заключается в том, что контрольная сумма не учитывает порядок байтов в посылке, то есть не является уникальным “отпечатком” всех данных. Например, данные повредились так, что из вот такого пакета
data.channel = 16;data.val_i = 12345;data.val_f = 3.1415;
Превратились в такой:
data.channel = 15;data.val_i = 12346;data.val_f = 3.1415;
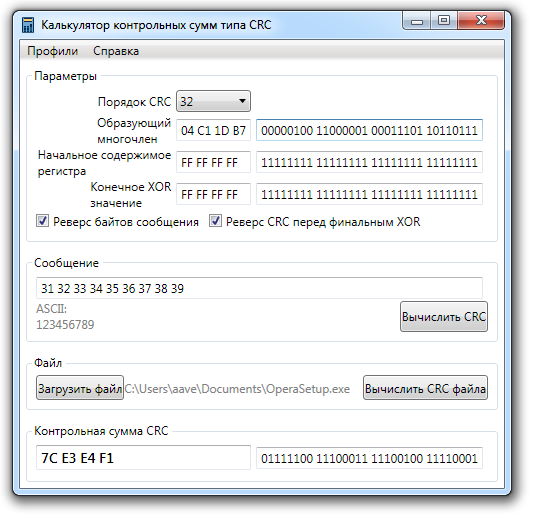
Но контрольная сумма всё равно будет 102! Также контрольная сумма фактически игнорирует нули, то есть любой набор данных со всеми нулями и условно одной единичкой будет обрабатываться одинаково (например 0, 0, 0, 1, 0, 0 и 0, 1, 0, 0, 0, 0), что также снижает надёжность. Поэтому рассмотрим более хитрый алгоритм, который называется CRC.
Немного истории
- 1996: Ганс Доббертин нашел псевдоколлизии в MD5, используя определенные инициализирующие векторы, отличные от стандартных.
- 2004: Китайские исследователи Ван Сяоюнь (Wang Xiaoyun), Фен Дэнгуо (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) объявили об обнаруженной ими уязвимости в алгоритме, позволяющей находить коллизии за крайне малое время (1 час на кластере IBM p690).
- 2005: Те же самые Ван Сяоюнь и Юй Хунбо опубликовали алгоритм, позволяющий найти две различные последовательности в 128 байт, которые дают одинаковый MD5-хэш.
- 2006: Чешский исследователь Властимил Клима опубликовал алгоритм, дающий возможность находить коллизии на обычном компьютере с любым начальным вектором (A,B,C,D) при помощи метода, названного им «туннелирование».
- 2007: Эдуардо Диаз по специально разработанной схеме создал два различных архива с двумя разными программами, но абсолютно идентичными MD5-хэшами.
- 2009: Дидье Стивенс использовал библиотеку evilize для создания двух разных программ с одинаковым кодом цифровой сигнатуры (Authenticode digital signature), authenticode используется Microsoft для подписи своих библиотек и исполняемых файлов.
Интуитивный подход
Мотивация
Voyager 2 — один из многих пользователей кодов четности для надежной связи.
Корректирующие коды имеют своим источником очень конкретную проблему, связанную с передачей данных. В некоторых случаях передача данных происходит по каналу связи, который не совсем надежен. Другими словами, данные, когда они циркулируют по этому каналу, могут быть повреждены. Цель контрольных сумм — обеспечить избыточность информации, чтобы можно было обнаружить ошибку.
В случае единственной контрольной суммы и в отличие от других кодов коррекции, таких как циклические коды , целью является не автоматическое исправление ошибок, а обнаружение. Затем коррекция выполняется новым запросом от получателя. Если циклические коды более эффективны, их алгоритмическая сложность растет, а также их размер.
Простая контрольная сумма просто складывает буквы сообщения. Он не может обнаруживать определенные типы ошибок. В частности, такая контрольная сумма инвариантна:
- реорганизация байтов сообщения
- добавление или удаление нулевых байтов
- множественные ошибки, компенсирующие друг друга.
Затем необходимо несколько контрольных сумм, и умножение иногда выходит из области двоичных полей для других более сложных структур конечных полей . Термин контрольная сумма все еще используется, хотя термин циклический контроль избыточности более уместен.
Этот тип кода принадлежит к семейству линейных кодов . Он был оформлен после Второй мировой войны . Клод Шеннон (1916, 2001) формализует теорию информации как раздел математики. Ричард Хэмминг (1915, 1998) специально работает над вопросом надежности кода для Bell Laboratories . Он развивает основы теории корректирующих кодов и формализует понятие контрольной суммы в ее общем виде.
Пример: бит четности
| 7-битные данные | Соглашение о паритете | |
|---|---|---|
| пара = 0 | нечетное = 0 | |
| 0000000 | 0000000 | 1 0000000 |
| 1010001 | 1 1010001 | 1010001 |
| 1101001 | 1101001 | 1 1101001 |
| 1111111 | 1 1111111 | 1111111 |
Предположим, целью является передача семи битов плюс бит четности. В случае последовательной передачи типа младший бит передается первым (lsb) в старший бит (msb), а затем бит четности.
Бит четности может быть определен как равный нулю, если сумма других битов четная, и единице в противном случае. Мы говорим о четности, то есть второй столбец таблицы называется четным = 0 . Сообщения, отправленные на восьми битах, всегда имеют нулевую четность , поэтому в случае ошибки ноль становится единицей или наоборот; получатель знает, что произошло изменение. Фактически, сумма битов становится нечетной, что невозможно без ошибки передачи.
Можно воспользоваться вторым соглашением, тогда бит четности определяется как равный единице, если сумма других битов четная, и нулю в противном случае. Результатом является третий столбец, обозначенный odd = 0 .
Бит четности выделен жирным шрифтом во втором и третьем столбцах.
Нельзя путать четность числа и то, что оно четное или нечетное (в математическом смысле этого слова). Двоичное число 00000011 (3 в десятичном числе) нечетное (не делится на 2), но имеет четность (четное количество бит в 1). Функция, которая связывает каждый вектор с его битом четности, называется функцией четности .
Такой подход позволяет обнаруживать количество нечетных ошибок в случае, когда буквы равны нулю или единице . Контрольная сумма обобщает концепцию обнаружения ошибок и для других алфавитов.
Сравнение ЛЮБЫХ данных ЛЮБЫХ баз (и РИБ, по правилам конвертаций) по контрольным суммам выбранных реквизитов, работающих на платформе 8.3… и выше
АКЦИЯ! При покупке данной разработки в МАЕ одну из 6 разработок получаете БЕСПЛАТНО! Данная обработка позволит Вам легко и просто, а главное — быстро, выполнить сравнение данных между ЛЮБЫМИ базами (и РИБ, по правилам конвертаций) по контрольным суммам выбранных объектов баз 1С, работающих на платформах 8.3 и выше. Удобный и понятный интерфейс в виде «мастера». Высокая скорость сравнения достигается за счет специального алгоритма расчета контрольной суммы объекта/записи и сравнения по данным суммам объектов 2х баз через файл. Имеется возможность выбора реквизитов, по которым система будет сравнивать объекты. Сравнение количества записей в движениях документов, возможность сравнивать данные по правилам конвертации и не только! Выбор объектов конфигурации для КАЖДОГО узла в отдельности с индивидуальным отбором для каждого объекта конфигурации, работа с FTP, сохранение или загрузка настроек, сохранение или загрузка результата сравнения, регистрация на обмен объекта и его движений.
14400 руб.
32
Определение хеша с помощью hashID
В некоторых случаях лезть в интернет для определения типа хеша будет затруднительно. В таких ситуациях можно использовать специальные утилиты. Одна из самых популярных на сегодняшний день — инструмент hashID.
Данная утилита пришла на смену утилит HashTag и Hash-Identifier.
hashID
— это чрезвычайно полезная тулза на Python 3, которая попытается определить, что за тип хеша перед ней.
В библиотеке hashID более двухсот различных сигнатур хешей и сервисов, которые их используют.
Утилита дружит с , а также без проблем запускается и на второй ветке Python.
Скачать hashID
Утилиту можно с Гитхаба. Там же найдете полный список поддерживаемых хешей в Excel-файле.
На этом все. Этих инструментов определения хеша вам должно хватить. Всем хорошего настроения и информационной безопасности!
Алгоритмы
Байт четности или слово четности
Простейший алгоритм контрольной суммы — это так называемая продольная проверка четности , которая разбивает данные на «слова» с фиксированным числом битов n , а затем вычисляет исключающее ИЛИ (XOR) для всех этих слов. Результат добавляется к сообщению в виде дополнительного слова. Чтобы проверить целостность сообщения, получатель вычисляет исключающее или всех его слов, включая контрольную сумму; если результатом не является слово, состоящее из n нулей, получатель знает, что произошла ошибка передачи.
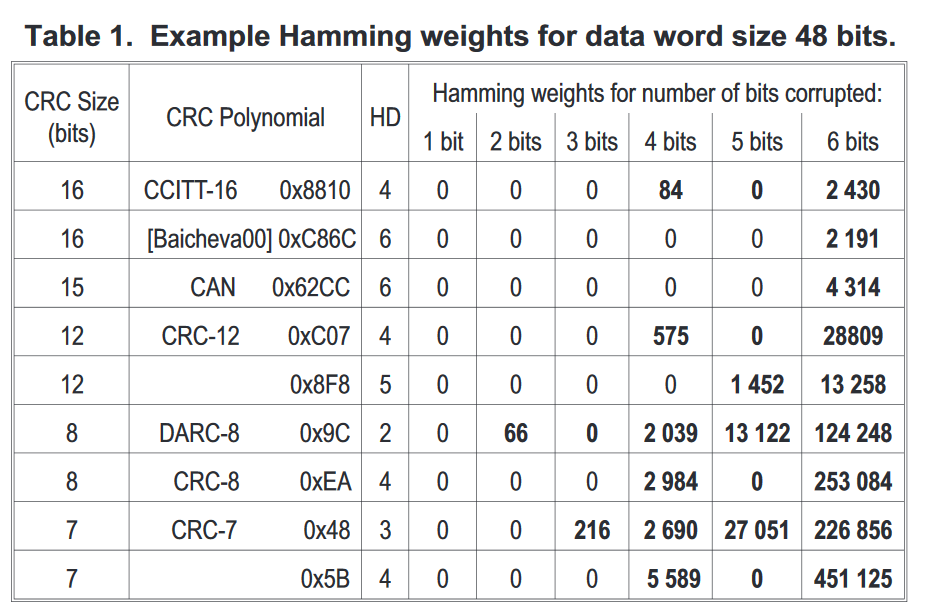
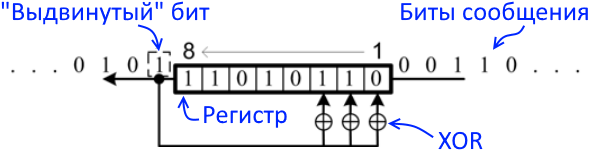
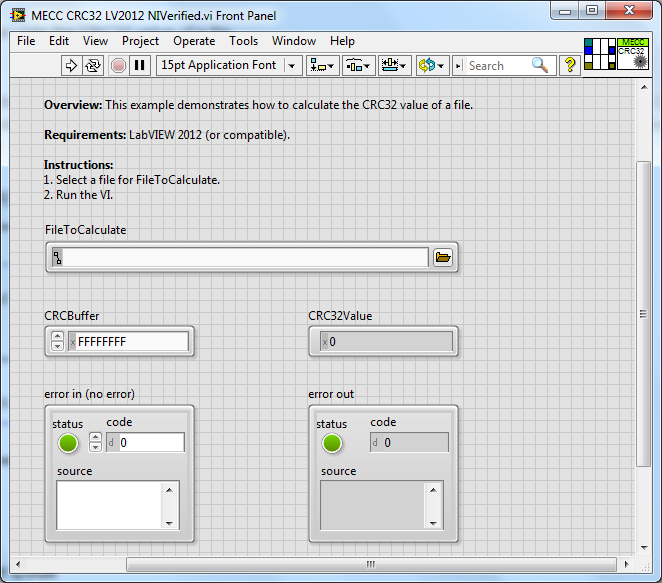

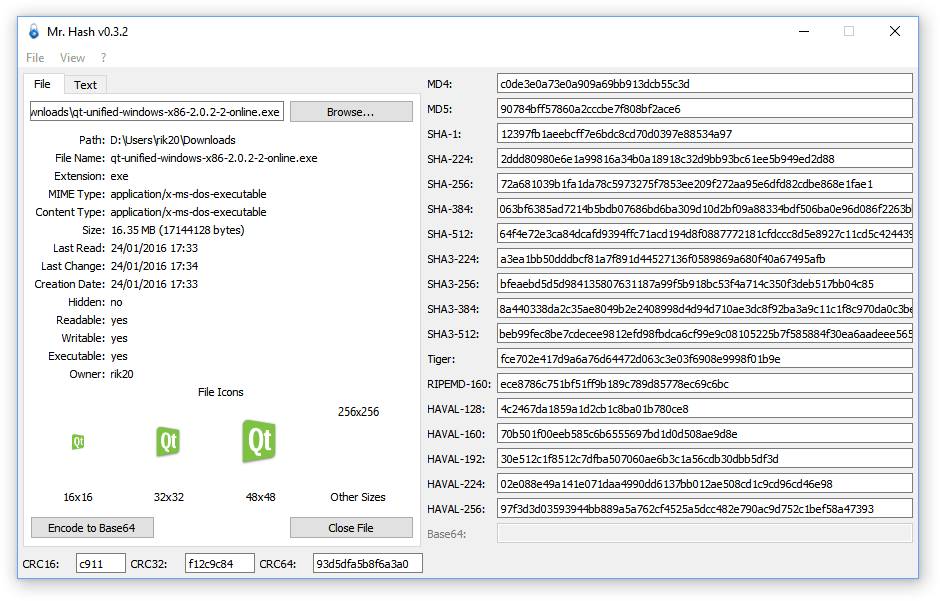
С этой контрольной суммой любая ошибка передачи, которая переворачивает один бит сообщения или нечетное количество битов, будет обнаружена как неправильная контрольная сумма. Однако ошибка, затрагивающая два бита, не будет обнаружена, если эти биты находятся в одной и той же позиции в двух разных словах. Также перестановка двух и более слов не будет обнаружена. Если затронутые биты независимо выбраны случайным образом, вероятность того, что двухбитовая ошибка не будет обнаружена, равна 1 / n .
Сумма дополнения
Вариант предыдущего алгоритма состоит в том, чтобы сложить все «слова» как двоичные числа без знака, отбросив любые биты переполнения, и добавить два дополнения к итоговой сумме в качестве контрольной суммы. Чтобы проверить сообщение, получатель таким же образом складывает все слова, включая контрольную сумму; если результат не является словом, полным нулей, вероятно, произошла ошибка. Этот вариант также обнаруживает любую однобитовую ошибку, но в SAE J1708 используется модульная сумма .
Зависит от позиции
Простые контрольные суммы, описанные выше, не позволяют обнаружить некоторые общие ошибки, которые затрагивают сразу несколько битов, такие как изменение порядка слов данных или вставка или удаление слов со всеми битами, установленными в ноль. Алгоритмы контрольной суммы, наиболее часто используемые на практике, такие как контрольная сумма Флетчера , Adler-32 и циклический контроль избыточности (CRC), устраняют эти недостатки, учитывая не только значение каждого слова, но и его позицию в последовательности. Эта функция обычно увеличивает стоимость вычисления контрольной суммы.
Нечеткая контрольная сумма
Идея нечеткой контрольной суммы была разработана для обнаружения спама в электронной почте путем создания совместных баз данных от нескольких интернет-провайдеров электронной почты, подозреваемой в спаме. Содержание такого спама часто может отличаться по деталям, что делает обычное вычисление контрольной суммы неэффективным. Напротив, «нечеткая контрольная сумма» сокращает основной текст до характерного минимума, а затем генерирует контрольную сумму обычным образом. Это значительно увеличивает вероятность того, что несколько различающиеся спам-письма будут давать одинаковую контрольную сумму. Программное обеспечение для обнаружения спама интернет-провайдеров, такое как SpamAssassin , сотрудничающих с ними интернет-провайдеров, отправляет контрольные суммы всех электронных писем в централизованную службу, такую как DCC . Если количество отправленных нечетких контрольных сумм превышает определенный порог, база данных отмечает, что это, вероятно, указывает на спам. Пользователи службы ISP аналогичным образом генерируют нечеткую контрольную сумму для каждого из своих электронных писем и запрашивают службу на предмет вероятности спама.
Общие Соображения
Сообщение длиной m бит можно рассматривать как угол m -мерного гиперкуба. Эффект алгоритма контрольной суммы, который дает n- битную контрольную сумму, заключается в отображении каждого m- битного сообщения в угол большего гиперкуба с размерностью m + n . В 2 м + п углов этого гиперкуба представляют все возможные принятые сообщения. Допустимые полученные сообщения (те, которые имеют правильную контрольную сумму) составляют меньший набор, с углами всего 2 м .
Тогда однобитовая ошибка передачи соответствует смещению от допустимого угла (правильное сообщение и контрольная сумма) к одному из m смежных углов. Ошибка, затрагивающая k бит, перемещает сообщение в угол, который на k шагов удаляется из его правильного угла. Целью хорошего алгоритма контрольной суммы является распространение действительных углов как можно дальше друг от друга, чтобы увеличить вероятность того, что «типичные» ошибки передачи окажутся в недопустимом углу.
Описание
В настоящее время практически ни одно приложение криптографии не обходится без использования хэширования.
Хэш-функции – это функции, предназначенные для «сжатия» произвольного сообщения или набора данных, записанных, как правило, в двоичном алфавите, в некоторую битовую комбинацию фиксированной длины, называемую сверткой. Хэш-функции имеют разнообразные применения при проведении статистических экспериментов, при тестировании логических устройств, при построении алгоритмов быстрого поиска и проверки целостности записей в базах данных. Основным требованием к хэш-функциям является равномерность распределения их значений при случайном выборе значений аргумента.
Криптографической хеш-функцией называется всякая хеш-функция, являющаяся криптостойкой, то есть удовлетворяющая ряду требований специфичных для криптографических приложений. В криптографии хэш-функции применяются для решения следующих задач:
- построения систем контроля целостности данных при их передаче или хранении,
- аутентификация источника данных.
Хэш-функцией называется всякая функция h:X -> Y, легко вычислимая и такая, что для любого сообщения M значение h(M) = H (свертка) имеет фиксированную битовую длину. X — множество всех сообщений, Y — множество двоичных векторов фиксированной длины. Как правило хэш-функции строят на основе так называемых одношаговых сжимающих функций y = f(x1, x2) двух переменных, где x1, x2 и y — двоичные векторы длины m, n и n соответственно, причем n — длина свертки, а m — длина блока сообщения.
Для получения значения h(M) сообщение сначала разбивается на блоки длины m (при этом, если длина сообщения не кратна m то последний блок неким специальным образом дополняется до полного), а затем к полученным блокам M1, M2,.., MN применяют следующую последовательную процедуру вычисления свертки:
Ho = v, Hi = f(Mi,Hi-1), i = 1,.., N, h(M) = HN Здесь v — некоторая константа, часто ее называют инициализирующим вектором. Она выбирается из различных соображений и может представлять собой секретную константу или набор случайных данных (выборку даты и времени, например).
При таком подходе свойства хэш-функции полностью определяются свойствами одношаговой сжимающей функции.
Выделяют два важных вида криптографических хэш-функций — ключевые и бесключевые. Ключевые хэш-функции называют кодами аутентификации сообщений. Они дают возможность без дополнительных средств гарантировать как правильность источника данных, так и целостность данных в системах с доверяющими друг другу пользователями.
Бесключевые хэш-функции называются кодами обнаружения ошибок. Они дают возможность с помощью дополнительных средств (шифрования, например) гарантировать целостность данных. Эти хэш-функции могут применяться в системах как с доверяющими, так и не доверяющими друг другу пользователями.