
Инструкция для Word
Если у вас нет программы Word, то скачайте ее с официального сайта разработчиков и установите на свой компьютер. Если вы не собираетесь постоянно использовать эту программу, то платить за нее не нужно, вам хватит пробной версии.
Нажмите на нужный файл правой клавишей мышки и откройте подменю «Открыть с помощью», укажите программу Word. Если данной программы нет в списке, то запустите Word обычным способом. Откройте меню «Файл» и выберите команду «Открыть», укажите расположение нужного документа на жестком диске и нажмите «Открыть». Будет предложено несколько вариантов открытия файла, связанных с его нестандартной кодировкой, укажите нужный и нажмите команду ОК. Подбор кодировки
Далее нужно изменить кодировку и сохранить результат, для этого откройте меню «Файл» и нажмите пункт «Сохранить как». Укажите директорию для измененного документа, впишите новое имя и выполните команду «Сохранить». Загрузится окно атрибутов документа, выберите нужную кодировку и нажмите Enter (наиболее используемой кодировкой является «Юникод»).
Внимательно отнеситесь к сохранению документа, если вы попытаетесь сохранить файл в прежнюю папку с прежним названием, то новый документ заменит собой старый файл
Чтобы сохранить на диске два разных документа, нужно использовать для них разные названия или папки.
При сохранении файла также обратите внимание на его расширение. Если документ в дальнейшем будет открываться с помощью программы Word 2003 года выпуска и более старшими версиями, то используйте формат doc
Если документ нужен для программы 2007 года и более новых версий, то подойдет формат docx. Также стоит помнить, что формат doc открывается как на старых версиях программы, так и на новых, но у них ограниченное форматирование. Стоит понимать, что отображение текстового документа не стандартными символами – это не только признак неизвестной кодировки, возможно в используемом редакторе нет нужного шрифта, в таком случае нужно менять не кодировку, а шрифт.
Это интересно: Как можно в фотошопе сделать рамку по контуру
Выбор кодировки
- Откройте вкладку Файл
- Выберите пункт Сохранить как
Чтобы сохранить файл в другой папке, найдите и откройте ее.
- В поле Имя файла
введите имя нового файла.
- В поле Тип файла
выберитеОбычный текст .
- Нажмите кнопку Сохранить
- Если появится диалоговое окно Microsoft Office Word — проверка совместимости
, нажмите кнопкуПродолжить .
- В диалоговом окне Преобразование файла
выберите подходящую кодировку.
- Чтобы использовать стандартную кодировку, выберите параметр
Windows (по умолчанию)
- Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS
- Чтобы задать другую кодировку, установите переключатель Другая
и выберите нужный пункт в списке. В областиОбразец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание:
Чтобы увеличить область отображения документа, можно изменить размер диалогового окнаПреобразование файла .
- Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
- Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк
и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в полеЗавершать строки .
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
|
Система письменности |
Кодировки |
Используемый шрифт |
|---|---|---|
|
Многоязычная |
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7) |
Стандартный шрифт для стиля «Обычный» локализованной версии Word |
|
Арабская |
Windows 1256, ASMO 708 |
|
|
Китайская (упрощенное письмо) |
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ |
|
|
Китайская (традиционное письмо) |
BIG5, EUC-TW, ISO-2022-TW |
|
|
Кириллица |
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866 |
|
|
Английская, западноевропейская и другие, основанные на латинице |
Windows 1250, 1252-1254, 1257, ISO8859-x |
|
|
Греческая |
||
|
Японская |
Shift-JIS, ISO-2022-JP (JIS), EUC-JP |
|
|
Корейская |
Wansung, Johab, ISO-2022-KR, EUC-KR |
|
|
Вьетнамская |
||
|
Индийские: тамильская |
||
|
Индийские: непальская |
ISCII 57002 (деванагари) |
|
|
Индийские: конкани |
ISCII 57002 (деванагари) |
|
|
Индийские: хинди |
ISCII 57002 (деванагари) |
|
|
Индийские: ассамская |
||
|
Индийские: бенгальская |
||
|
Индийские: гуджарати |
||
|
Индийские: каннада |
||
|
Индийские: малаялам |
||
|
Индийские: ория |
||
|
Индийские: маратхи |
ISCII 57002 (деванагари) |
|
|
Индийские: панджаби |
||
|
Индийские: санскрит |
ISCII 57002 (деванагари) |
|
|
Индийские: телугу |
Для использования индийских языков необходима их поддержка в операционной системе и наличие соответствующих шрифтов OpenType.
Для непальского, ассамского, бенгальского, гуджарати, малаялам и ория доступна только ограниченная поддержка.
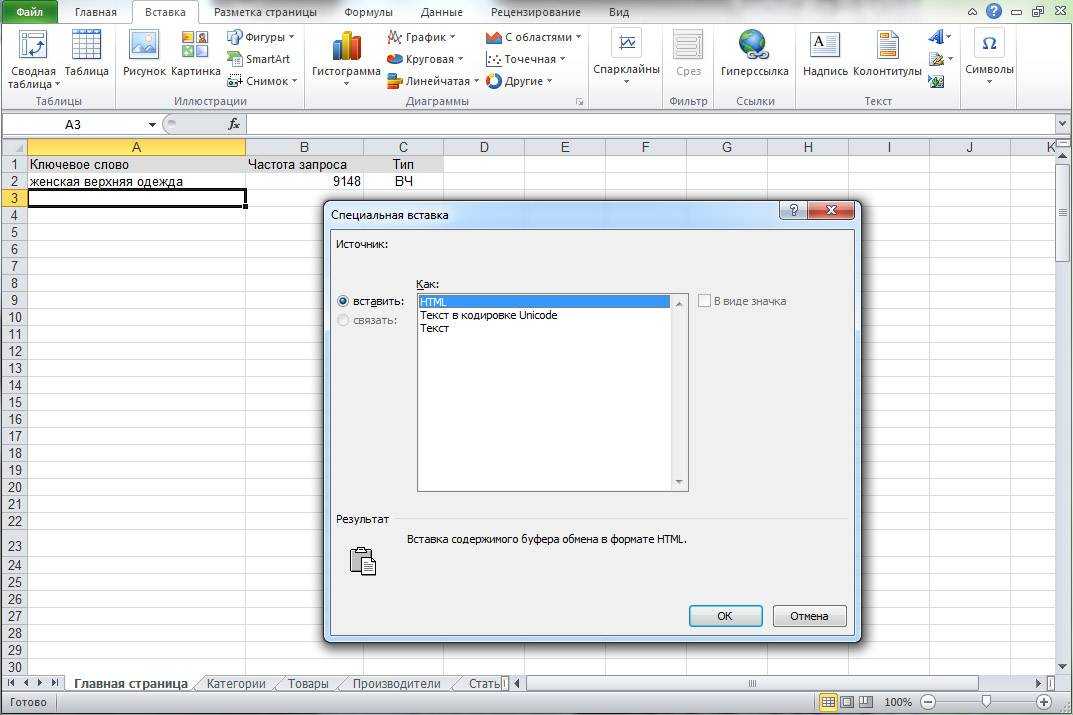
Иногда открыв файл, созданный при помощи Microsoft Word и присланный нам по почте, скайпу или другим способом, мы вместо привычных русских слов видим какие-то странные иероглифы. Мы недоумеваем, что же такое нам прислали, связываемся с отправителем, а он говорит, что у него все нормально открывается. Суть данной проблемы скорее всего состоит в том, что файл был сохранен не в той кодировке, что стоит по умолчанию в вашей программе. Чтобы исправить ситуацию необходимо всего лишь поменять кодировку файла и сейчас мы узнаем, как это сделать.
В данном примере будет использоваться Microsoft Word 2010 но принцип решения нашей задачи будет таким же и во всех остальных версиях программы. Итак, открываем наш «проблемный» документ, переходим в меню Файл и нажимаем на пункте Параметры.
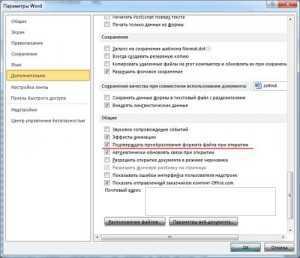
Нажимаем Ок и закрываем наш документ. Затем снова открываем его и перед нами должно появится окошко Преобразование файла, в нем нам нужно выбрать пункт Кодированный текст.
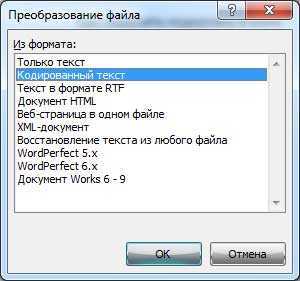
После этого появится другое окно, в котором нам нужно будет выбрать кодировку для своего файла. Ставим галочку на пункте Другая и в поле выбора пробуем методом перебора различные кодировки, до тех пор пока не получим результат. В окне Результат вы можете увидеть, как меняется текст в зависимости от выбранной вами кодировки.
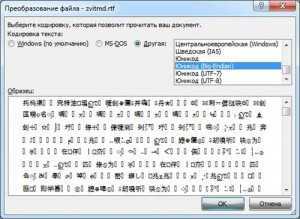
Если вышеописанный метод не помог исправить проблему, то возможно она кроется не в неправильной кодировке, а в отсутствии на вашем компьютере шрифта, с использованием которого создавался данный документ. В таком случае вам придется уточнить у отправителя документа название шрифта и установить нужный шрифт на свой компьютер.
Остались вопросы? — Мы БЕСПЛАТНО ответим на них в
Каким образом компьютер способен воспринимать, разделять и распознавать всё множество команд? Все символы, которыми мы пользуемся, представляют собой набор чисел. Другими словами, каждая буква и любой другой знак имеет своё обозначение в виде числа. Так компьютерной системе гораздо легче и быстрее обрабатывать информацию. Но не стоит забывать о том, что в мире множество языков, а для обозначения команд используется всего 256 символов. Поэтому существуют различные кодировки.
Кодировка — это способ сохранения информации, данных для последующего использования. Если на экране мы видим набор непонятных нам букв, это означает, что кодировка выбрана неправильно. И эти самые 256 цифр обозначают символы, записанные под их значениями, на иностранном языке. При возникновении этой проблемы компьютер при открытии файла предлагает изменить кодировку на другую, имеющуюся у него. Обычно кодировка определяется автоматически по выбранному языку (раскладке клавиатуры) на компьютере.
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Инструкция для Notepad++
Теперь давайте посмотрим, как обстоят дела в более профессиональном текстовом редакторе. Для смены кодировки текстовой информации в верхнем меню рабочего интерфейса есть специальный раздел. Сейчас покажу на скриншоте.
Если кликнуть мышкой по соответствующему разделу, то появится нужный список. Остается только сделать выбор и сохранить новые изменения.
Как видите, изменять кодировку текста при помощи блокнотов достаточно просто. Нужно лишь выполнить несколько не сложных действий.
Стоит упомянуть, что Notepad++ весьма удобен для редактирования различных кодов. Например, PHP, HTML. Собственно, поэтому он широко распространен среди многих пользователей, которые периодически работают с исходным кодом, например, тех же сайтов. Что уж говорить, я сам периодическим им пользуюсь. Много места на диске не занимает, работает быстро, коды просматривать и редактировать удобно. Ладно, на этом завершу мысль, не буду превращать эту статью в обзор хорошего программного обеспечения для конкретных целей. Хотя, в будущем, скорее всего, еще вернусь к данной теме.
Кстати, а вы знаете, что этот самый блог посвящен темам финансов и заработков в интернете. К примеру, знаете, как зарабатывают на копирайтинге, на сайтах или арбитраже трафика? Есть множество профессиональных тонкостей и перспективных направлений деятельности.
Типы кодировок
Существует несколько типов кодировок:
- ASCII – первая кодировка, которая была признана Американским национальным институтом мировых стандартов. Для ее использования задействуется 7 бит, где первые 128 значений включают в себя весь английский алфавит, числа, знаки и символы. Такая кодировка ранее использовалась на англоязычных ресурсах.
- Кириллица – вариант российской кодировки, используемый на русскоязычных сайтах и блогах.
- КОИ8 (код обмена информацией 8-битный) – была разработана для кодирования букв кириллических алфавитов. Распространена в Unix-подобных ОС и электронной почте. Постепенно исчезает в связи с приходом Юникода.
- Windows 1250-1258 – 8-битные кодировки, зародившиеся после появления операционной системы Windows. Например, 1250 – все языки центральной Европы, 1251 – кириллица. В ней присутствуют все буквы русского алфавита, а также символы (за исключением знака ударения).
- UTF-8 – наиболее используемый тип кодировок, работающий практически со всеми языками мира. Символы занимают от 1 до 4 байт, что дает возможность создавать мультиязычные веб-сайты. Помимо UTF-8, есть такие варианты, как UTF-16 и UTF-32, однако предпочтение отдается первому типу.
Существуют и другие типы кодировок, но они используются в меньшей степени либо не используются вообще.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
iconv опция iconv опции -f из-кодировки -t в-кодировку файл(ы) ввода -o файлы вывода
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:
iconv -l
Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
������� � �������� ������ ����...
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
enca -i mypoem_draft.txt cat mypoem_draft.txt iconv -f CP1251 -t UTF-8//TRANSLIT mypoem_draft.txt -o poem.txt cat poem.txt enca -i poem.txt
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном.
Внимание! Следующая команда изменяет исходный файл, при этом иногда его просто обнуляет. Поэтому обязательно начните с создания резервной копии:
cp mypoem_draft.txt mypoem_draft.txt.bac
Желаемую кодировку нужно указать после ключа -x:
enca -x UTF-8 mypoem_draft.txt
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:
echo $'СТРОКА_ДЛЯ_ИЗМЕНЕНИЯ_КОДИРОВКИ' | iconv -f 'ЖЕЛАЕМАЯ_КОДИРОВКА'
Пример:
echo $'\xed\xe5 \xed\xe0\xe9\xe4\xe5\xed \xf3\xea\xe0\xe7\xe0\xed\xed\xfb\xe9 \xec\xee\xe4\xf3\xeb\xfc' | iconv -f 'Windows-1251' не найден указанный модуль
Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Программы для определения кодировки в Linux
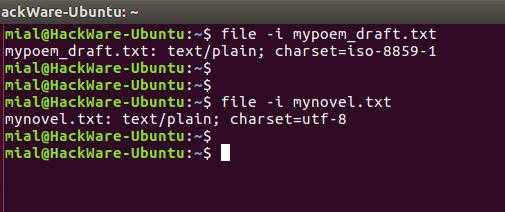
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:
file -i mypoem_draft.txt file -i mynovel.txt
Связанная статья: Инструкция по использованию команды file
Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
sudo apt install enca
Примеры использования:
enca mypoem_draft.txt enca mynovel.txt
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
MS-Windows code page 1251 LF line terminators
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
enca -e mypoem_draft.txt CP1251/LF
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
enca -i mypoem_draft.txt CP1251
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
enca -m mypoem_draft.txt windows-1251
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
enca -m -L russian mypoem_draft.txt
Чтобы узнать список доступных языков наберите:
enca --list languages
Вы увидите:
belarusian: CP1251 IBM866 ISO-8859-5 KOI8-UNI maccyr IBM855 KOI8-U
bulgarian: CP1251 ISO-8859-5 IBM855 maccyr ECMA-113
czech: ISO-8859-2 CP1250 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
estonian: ISO-8859-4 CP1257 IBM775 ISO-8859-13 macce baltic
croatian: CP1250 ISO-8859-2 IBM852 macce CORK
hungarian: ISO-8859-2 CP1250 IBM852 macce CORK
lithuanian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
latvian: CP1257 ISO-8859-4 IBM775 ISO-8859-13 macce baltic
polish: ISO-8859-2 CP1250 IBM852 macce ISO-8859-13 ISO-8859-16 baltic CORK
russian: KOI8-R CP1251 ISO-8859-5 IBM866 maccyr
slovak: CP1250 ISO-8859-2 IBM852 KEYBCS2 macce KOI-8_CS_2 CORK
slovene: ISO-8859-2 CP1250 IBM852 macce CORK
ukrainian: CP1251 IBM855 ISO-8859-5 CP1125 KOI8-U maccyr
chinese: GBK BIG5 HZ
none:
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Работа с кодировкой текста
Кодировка текста – эта набор электронных цифровых выражений, которые преобразуются в понятные для пользователя символы. Существует много видов кодировки, у каждого из которых имеются свои правила и язык. Умение программы распознавать конкретный язык и переводить его на понятные для обычного человека знаки (буквы, цифры, другие символы) определяет, сможет ли приложение работать с конкретным текстом или нет. Среди популярных текстовых кодировок следует выделить такие:
Последнее наименование является самым распространенным среди кодировок в мире, так как считается своего рода универсальным стандартом.
Чаще всего, программа сама распознаёт кодировку и автоматически переключается на неё, но в отдельных случаях пользователю нужно указать приложению её вид. Только тогда оно сможет корректно работать с кодированными символами.

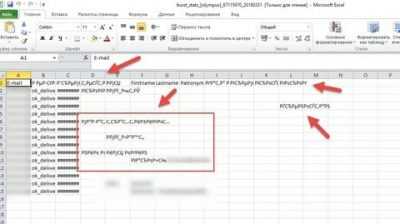
Наибольшее количество проблем с расшифровкой кодировки у программы Excel встречается при попытке открытия файлов CSV или экспорте файлов txt. Часто, вместо обычных букв при открытии этих файлов через Эксель, мы можем наблюдать непонятные символы, так называемые «кракозябры». В этих случаях пользователю нужно совершить определенные манипуляции для того, чтобы программа начала корректно отображать данные. Существует несколько способов решения данной проблемы.
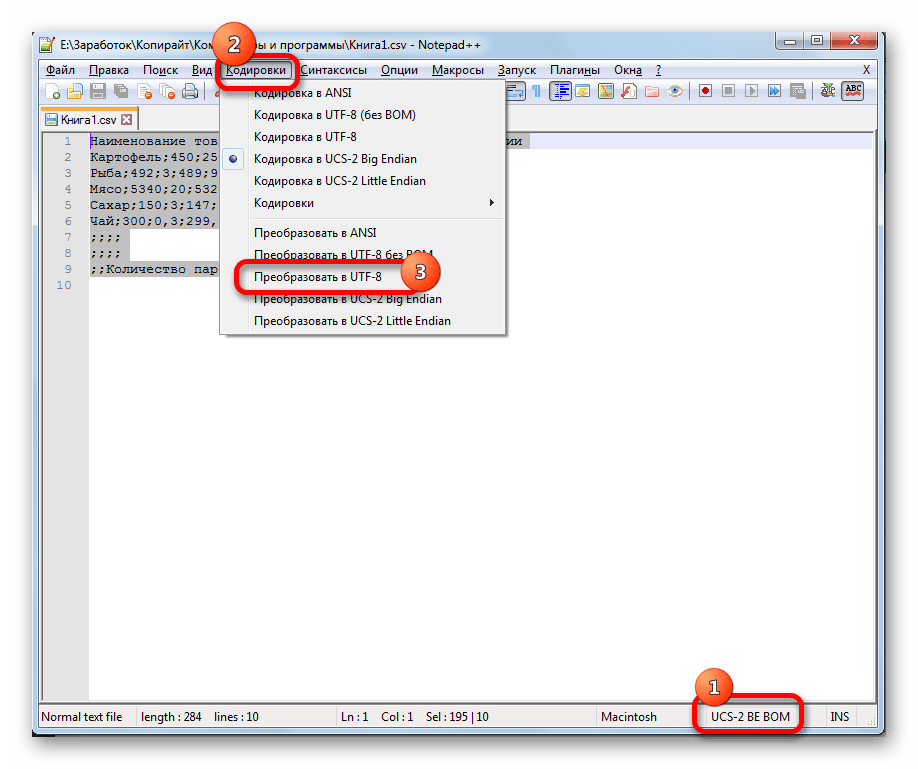
Способ 1: изменение кодировки с помощью Notepad++
К сожалению, полноценного инструмента, который позволял бы быстро изменять кодировку в любом типе текстов у Эксель нет. Поэтому приходится в этих целях использовать многошаговые решения или прибегать к помощи сторонних приложений. Одним из самых надежных способов является использование текстового редактора Notepad++.
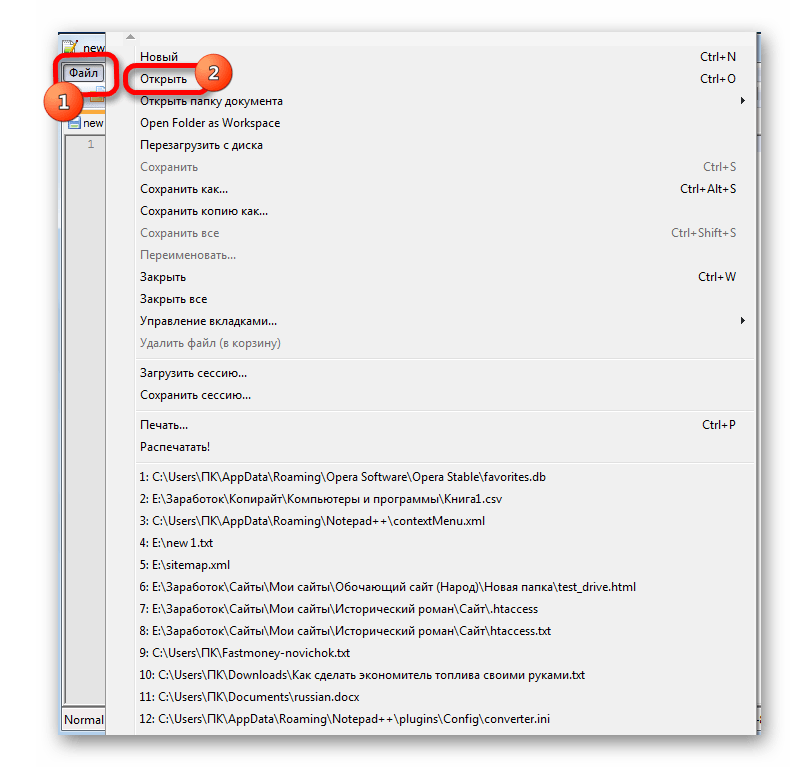
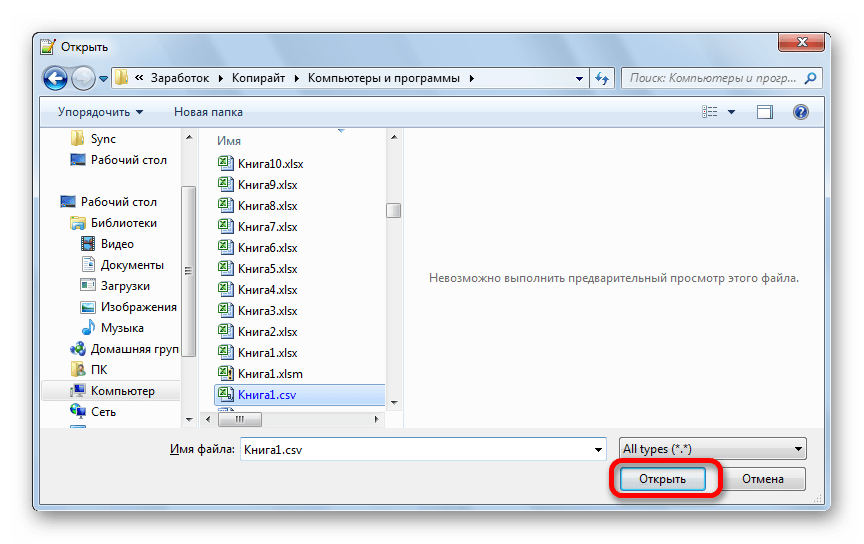

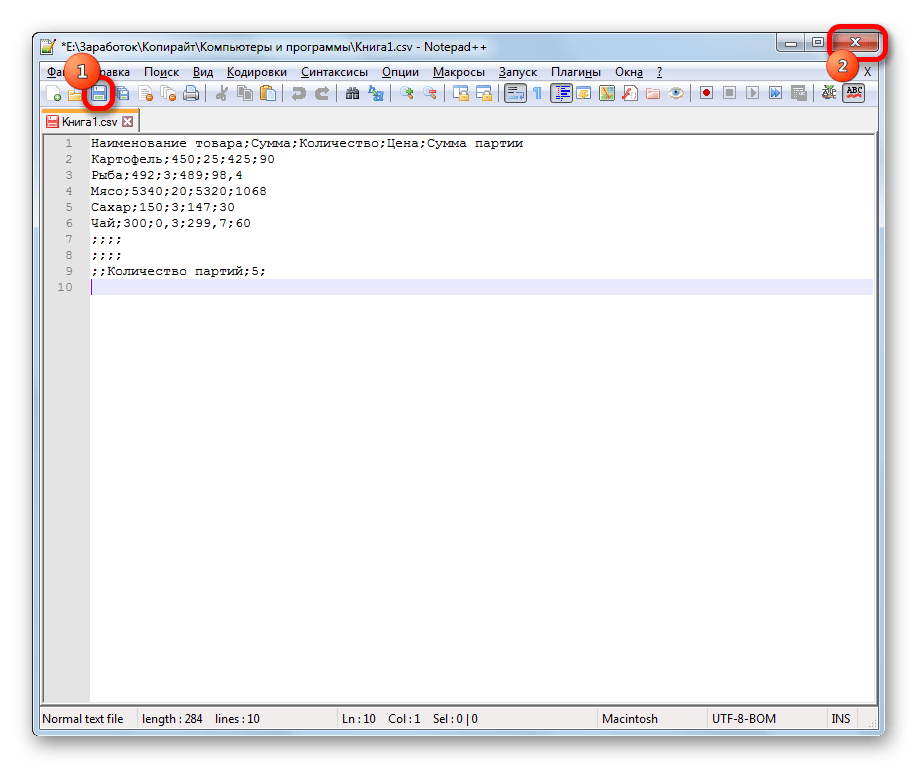
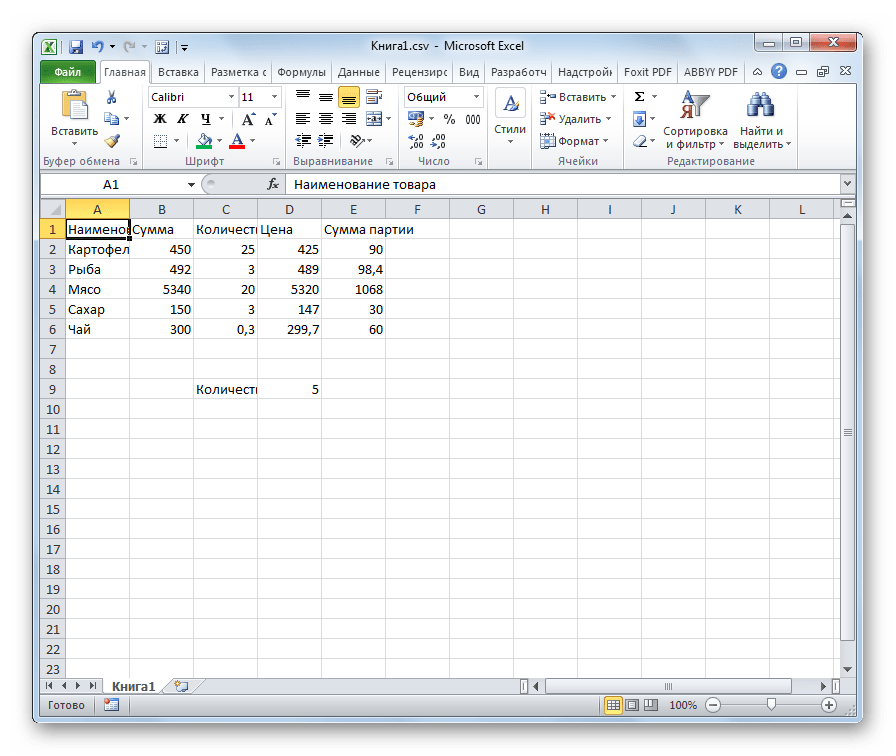
Несмотря на то, что данный способ основан на использовании стороннего программного обеспечения, он является одним из самых простых вариантов для перекодировки содержимого файлов под Эксель.
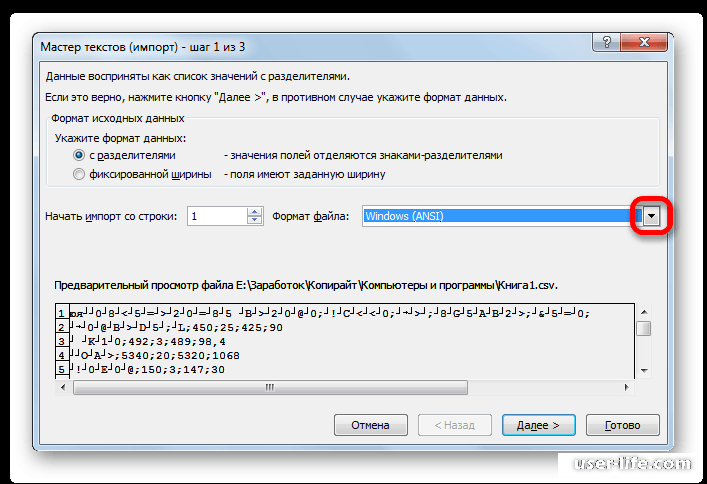
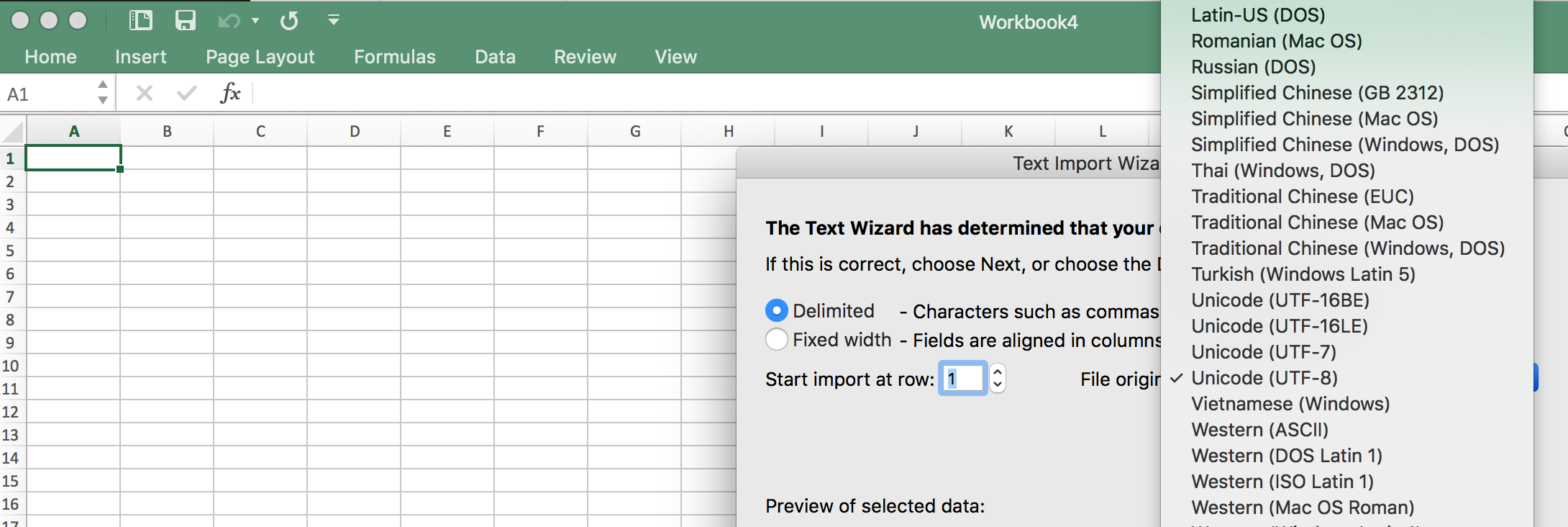
Способ 2: применение Мастера текстов
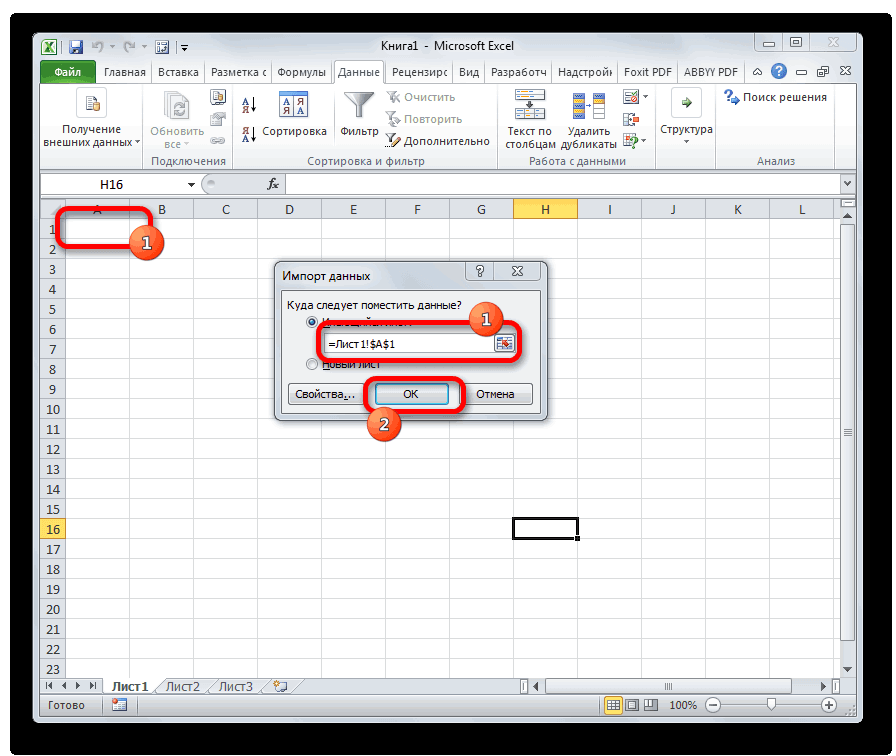
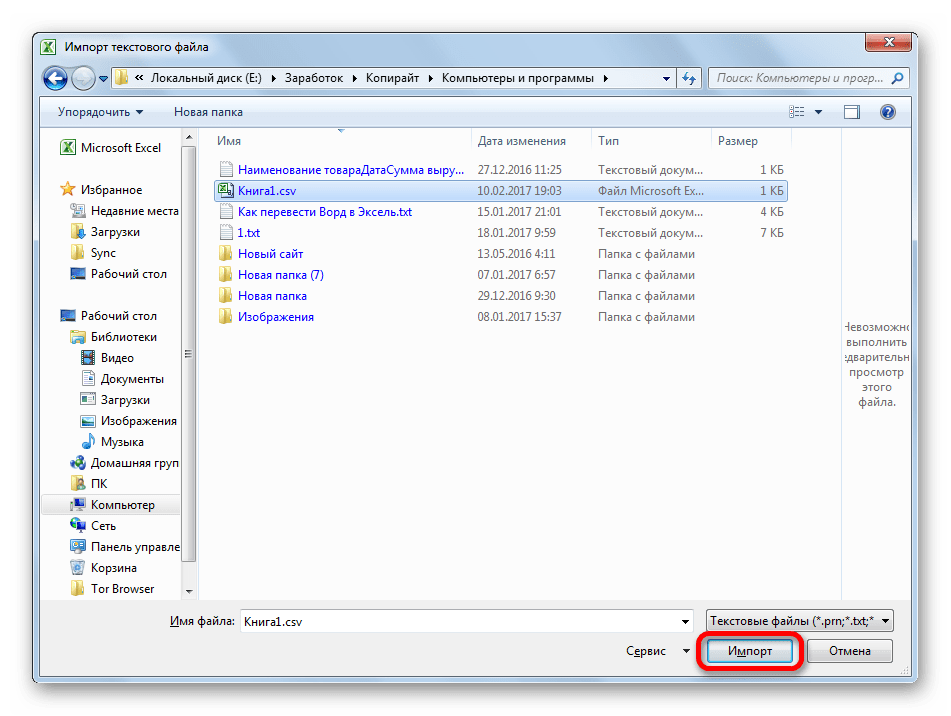
Кроме того, совершить преобразование можно и с помощью встроенных инструментов программы, а именно Мастера текстов. Как ни странно, использование данного инструмента несколько сложнее, чем применение сторонней программы, описанной в предыдущем методе.

Переходим в директорию размещения импортируемого файла, выделяем его и кликаем по кнопке «Импорт».

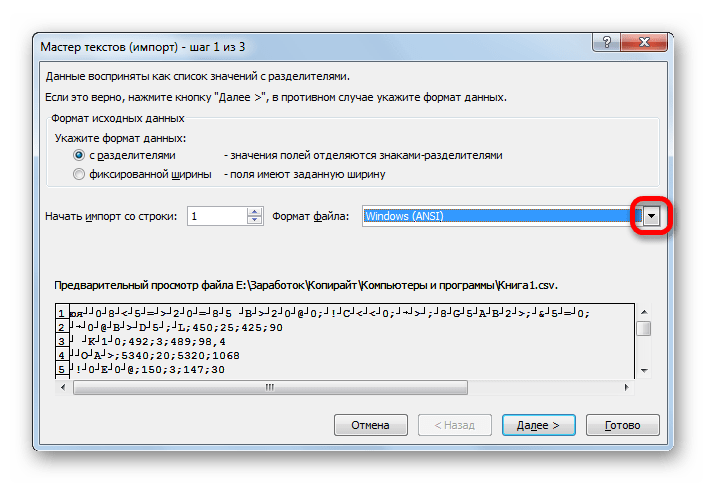
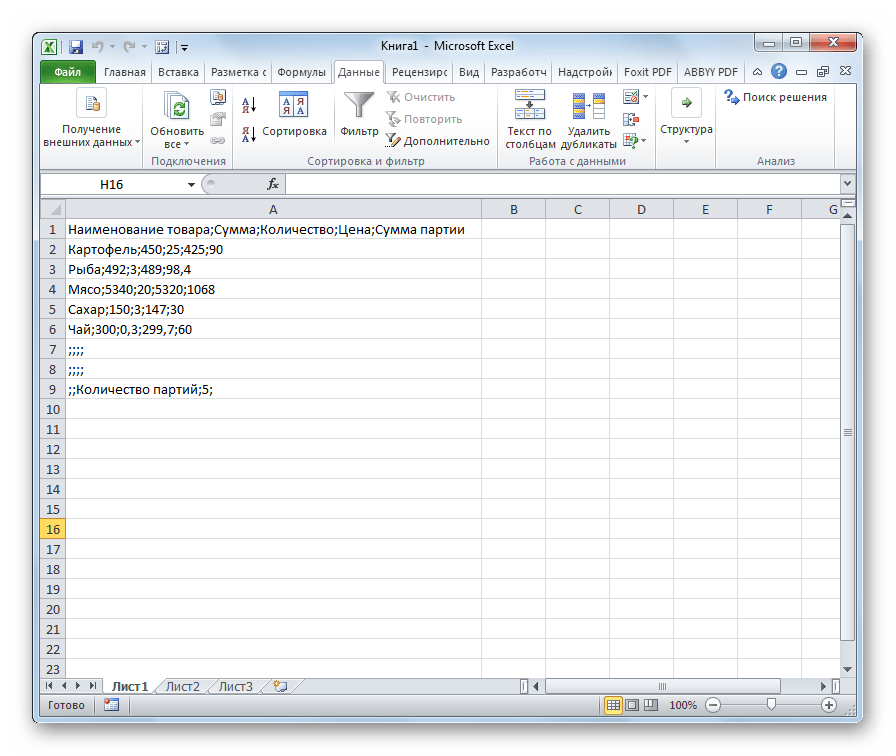
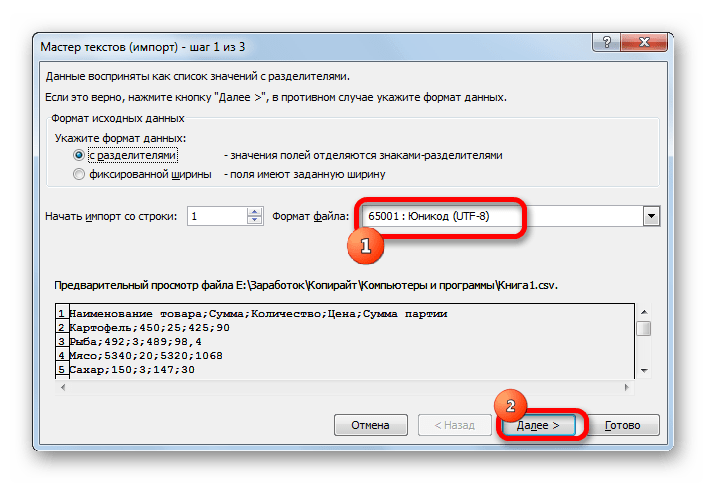
Если данные отображаются все равно некорректно, то пытаемся экспериментировать с применением других кодировок, пока текст в поле для предпросмотра не станет читаемым. После того, как результат удовлетворит вас, жмите на кнопку «Далее».
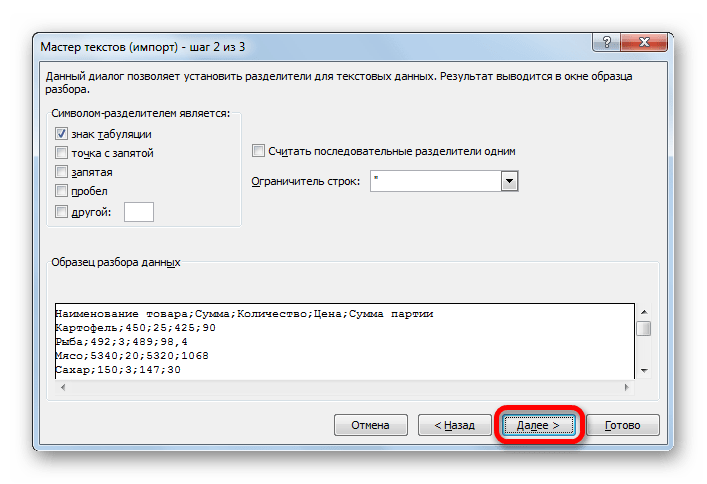
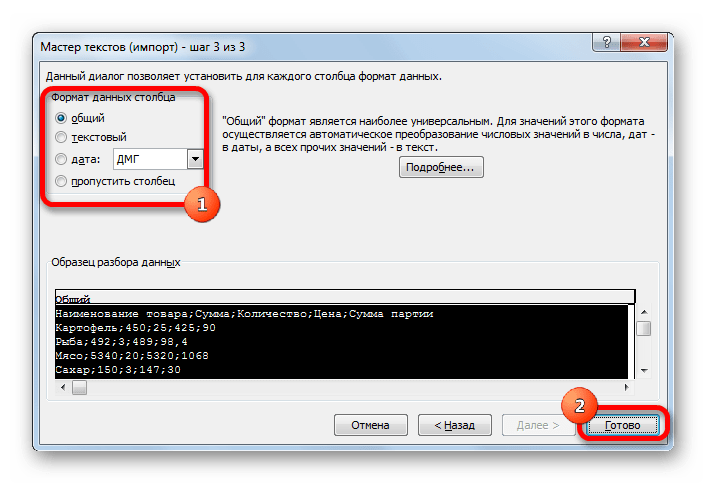
Тут настройки следует выставить, учитывая характер обрабатываемого контента. После этого жмем на кнопку «Готово».
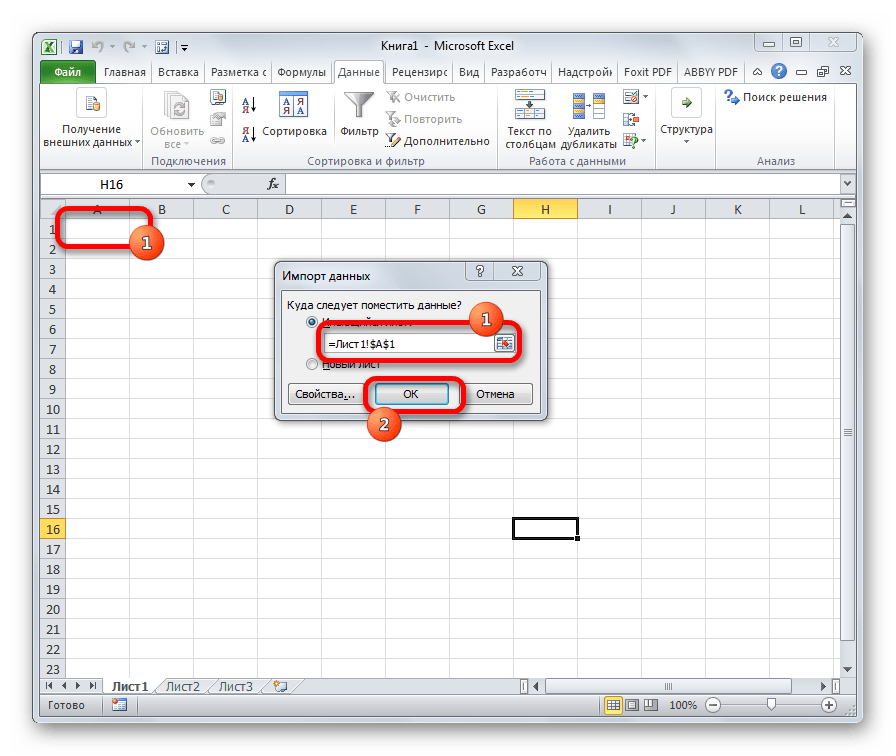

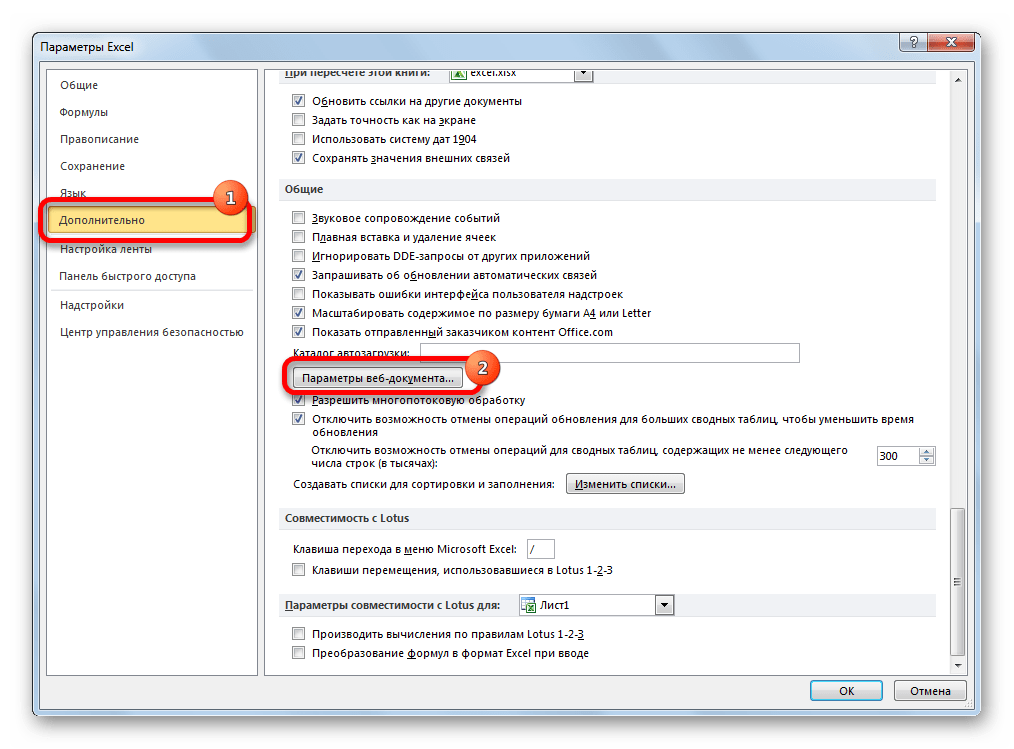
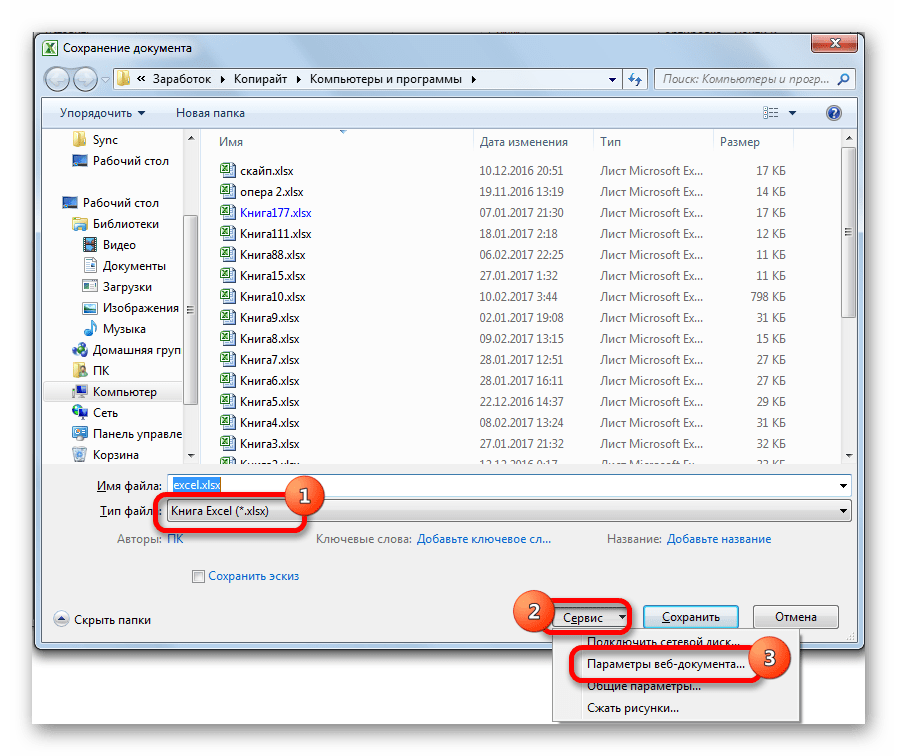
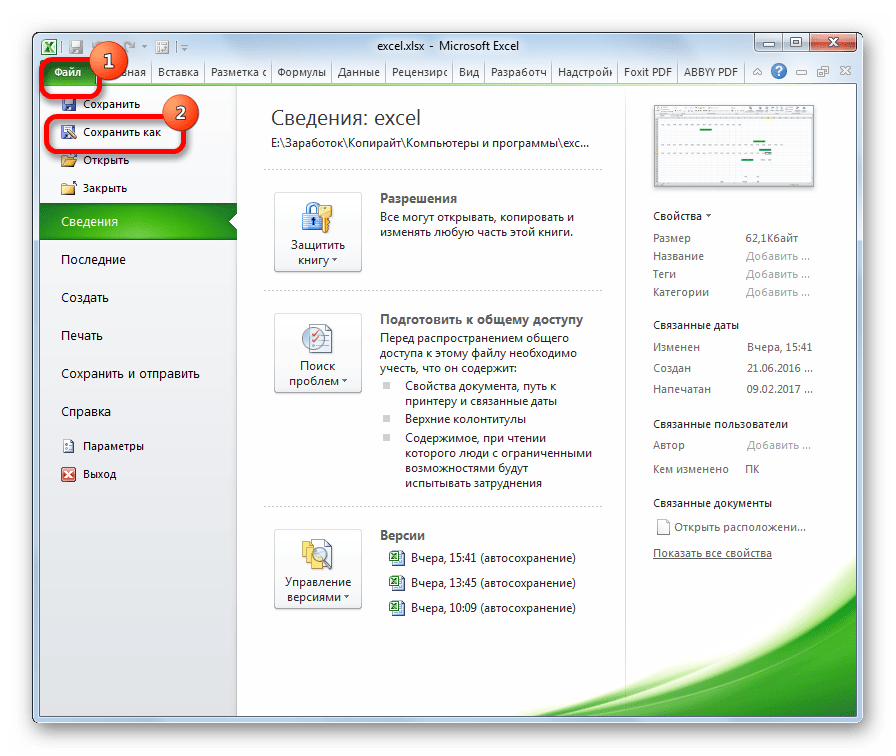
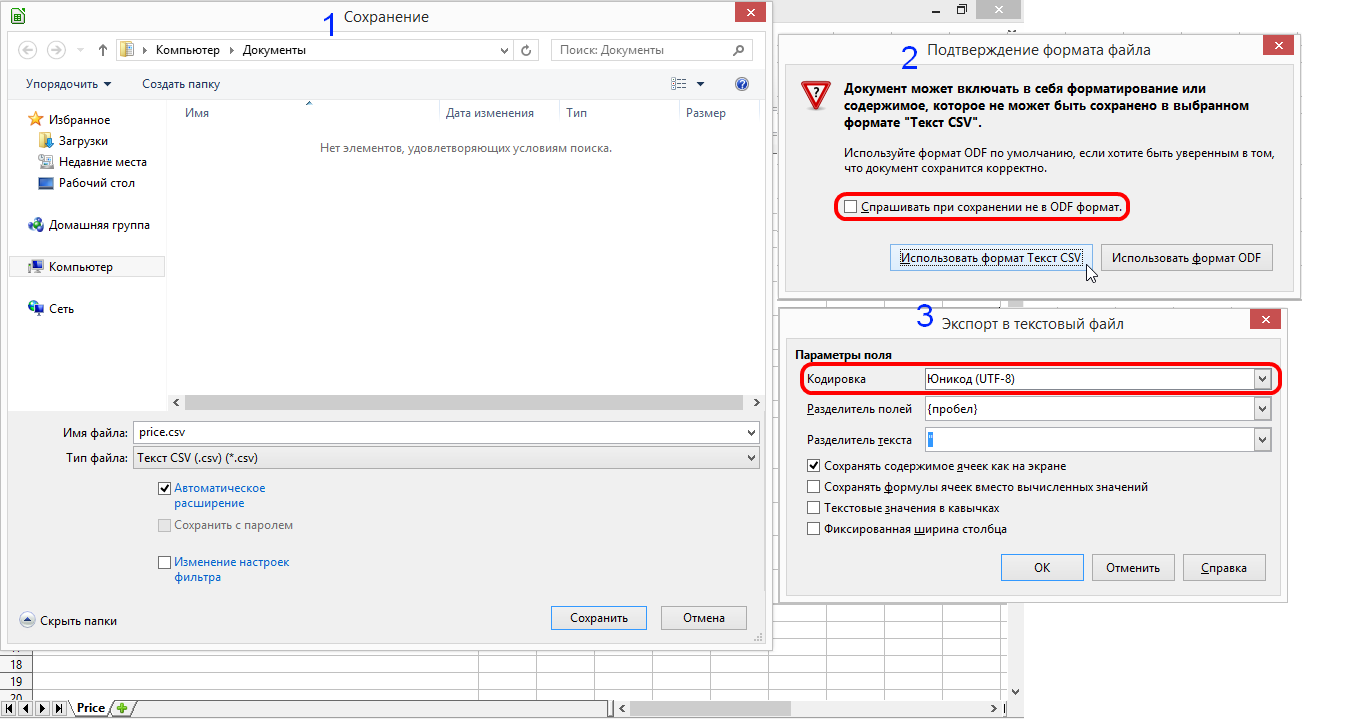
Способ 3: сохранение файла в определенной кодировке
Бывает и обратная ситуация, когда файл нужно не открыть с корректным отображением данных, а сохранить в установленной кодировке. В Экселе можно выполнить и эту задачу.


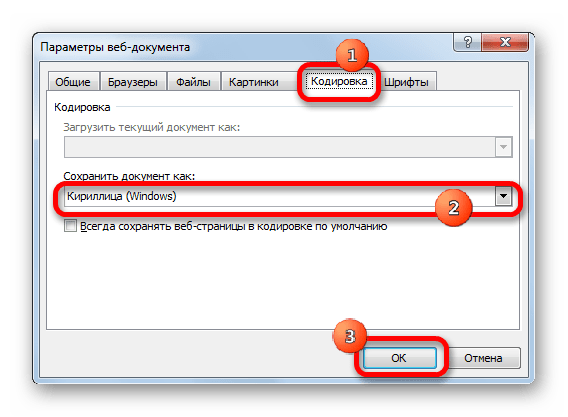
Документ сохранится на жестком диске или съемном носителе в той кодировке, которую вы определили сами. Но нужно учесть, что теперь всегда документы, сохраненные в Excel, будут сохраняться в данной кодировке. Для того, чтобы изменить это, придется опять заходить в окно «Параметры веб-документа» и менять настройки.
Существует и другой путь к изменению настроек кодировки сохраненного текста.
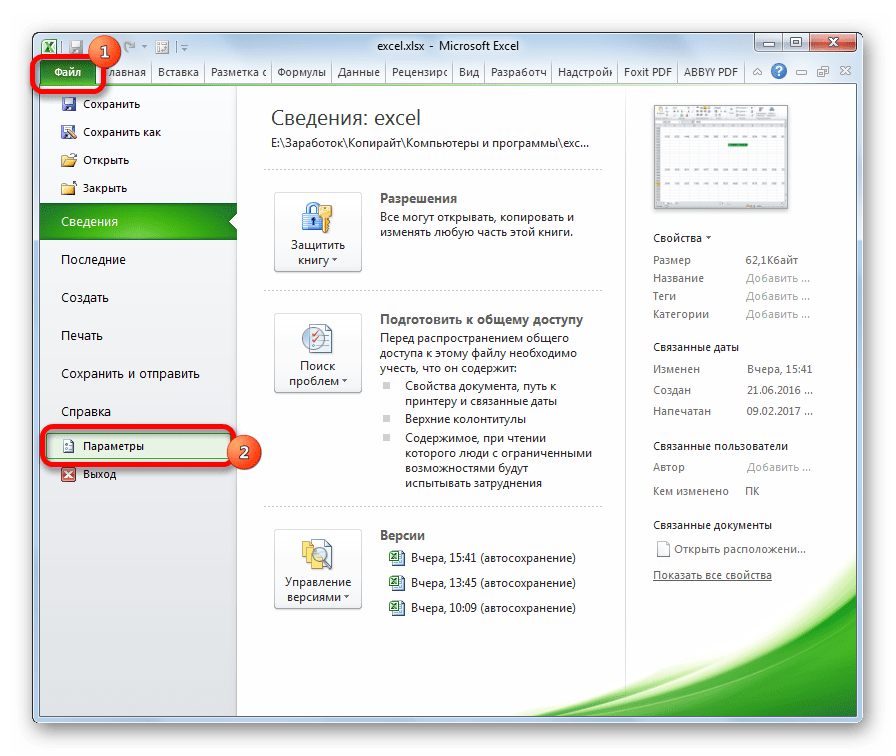

Теперь любой документ, сохраненный в Excel, будет иметь именно ту кодировку, которая была вами установлена.
Как видим, у Эксель нет инструмента, который позволил бы быстро и удобно конвертировать текст из одной кодировки в другую. Мастер текста имеет слишком громоздкий функционал и обладает множеством не нужных для подобной процедуры возможностей. Используя его, вам придется проходить несколько шагов, которые непосредственно на данный процесс не влияют, а служат для других целей. Даже конвертация через сторонний текстовый редактор Notepad++ в этом случае выглядит несколько проще. Сохранение файлов в заданной кодировке в приложении Excel тоже усложнено тем фактом, что каждый раз при желании сменить данный параметр, вам придется изменять глобальные настройки программы.
Как поменять кодировку в программе?
Для работы с таблицей, в которой используется стандарт, не заданный по умолчанию в программе, надо изменить кодировку. Существует несколько способов.
При помощи Notepad
Если в Экселе не получается превратить «кракозябры» в нормальный текст, откройте файл в программе «Notepad++». Она распространяется бесплатно. Настройте там отображение символов, а потом продолжайте работать в Excel.
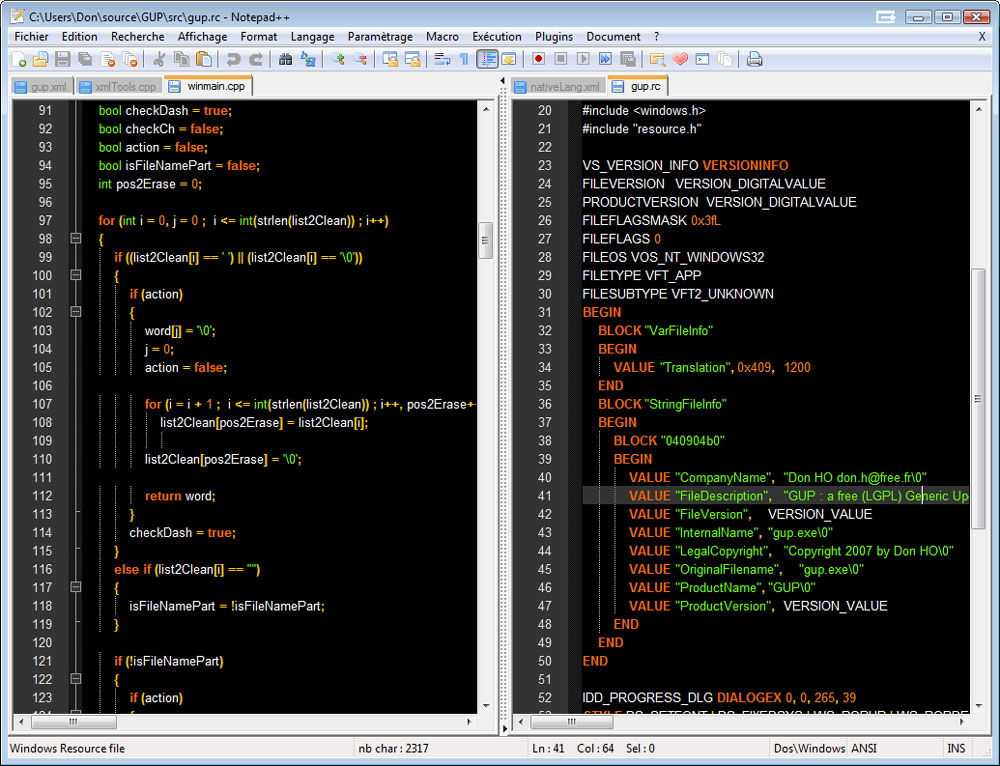
Откройте файл в программе «Notepad++»
- Создайте резервную копию документа. Или сохраните информацию из него в какой-нибудь другой таблице.
- Запустите Notepad.
- Перейдите в Файл — Открыть (File — Open) и укажите путь к таблице. В поле «Тип файла» поставьте «Все типы» («All types»). Или укажите конкретный формат. Таблицы имеют расширения .cvs, .xls, .xltm, xlam, .xlm. В Нотпаде текст отобразится без сетки. В нём ничего не надо редактировать.
- Справа внизу в строке состояния будет изображён стандарт, используемый сейчас.
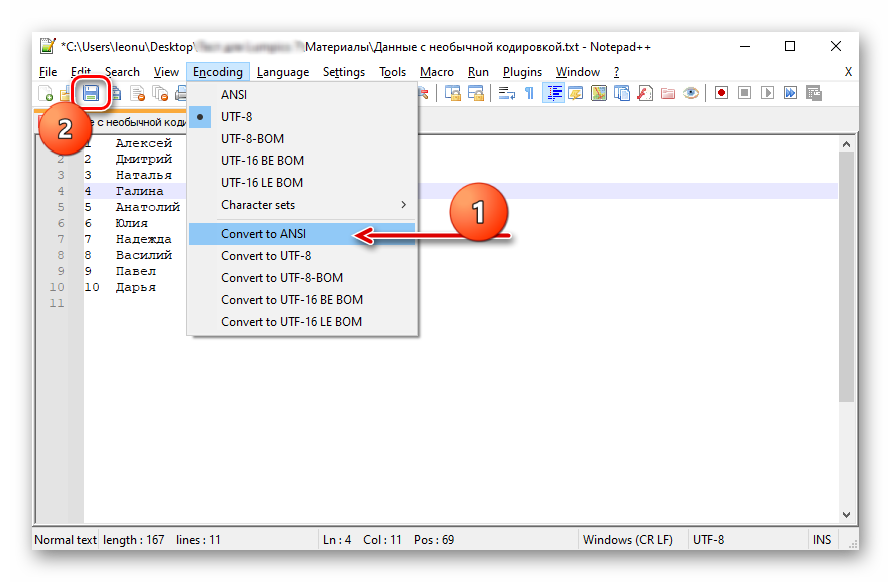
- Откройте меню Кодировка (Encoding). Оно находится вверху окна.
- Нажмите «Преобразовать в UTF-8» («Convert to UTF-8»). Документ будет конвертирован в нужный формат. Этот стандарт Excel воспринимает нормально и не станет превращать в бессвязный поток странных символов.
- Теперь выберите, какие знаки необходимо использовать. В том же меню Encoding наведите выпадающий список. Он там один.
- Для русского языка выберите Кириллица — Windows-1251. Если текст, скажем, на арабском или греческом — отметьте соответствующий набор символов. В разных странах используются разные стандарты.
- Программа попросит подтвердить действие.
- Если это не помогло, попробуйте другие кириллические шрифты.
- Сохранять текст надо тоже в экселевском формате.
Откройте файл в utf-8
Через интерфейс программы
Вот как сменить кодировку в Excel, используя встроенные возможности:
- Запустите программу. Не надо открывать заполненный документ. Нужен «чистый» лист.
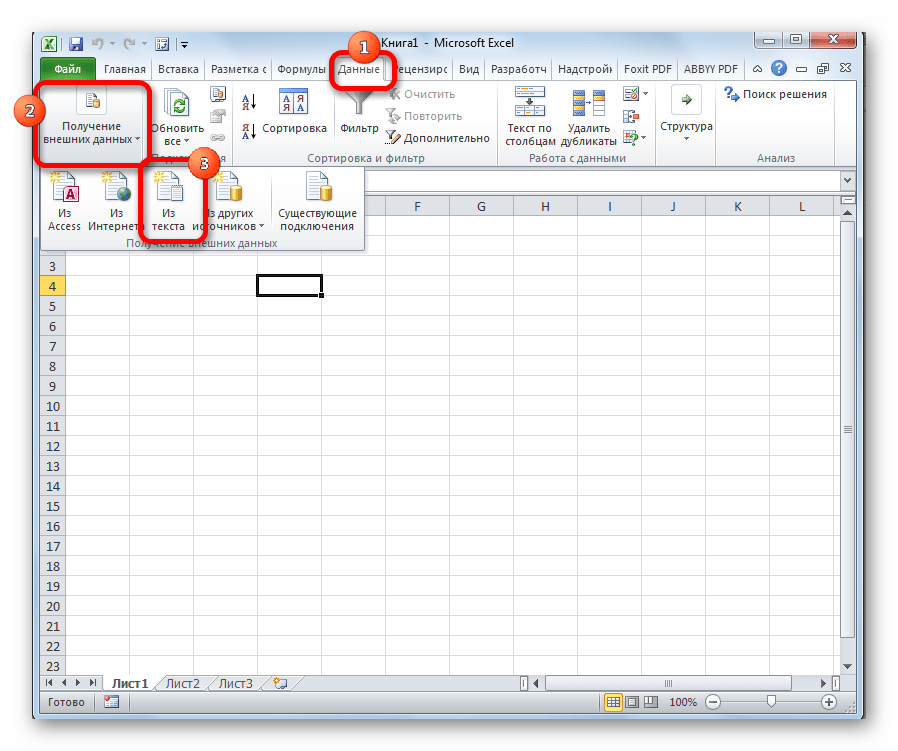
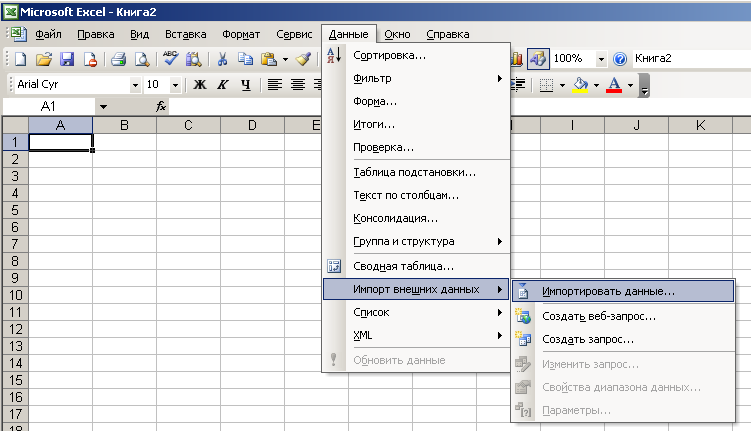
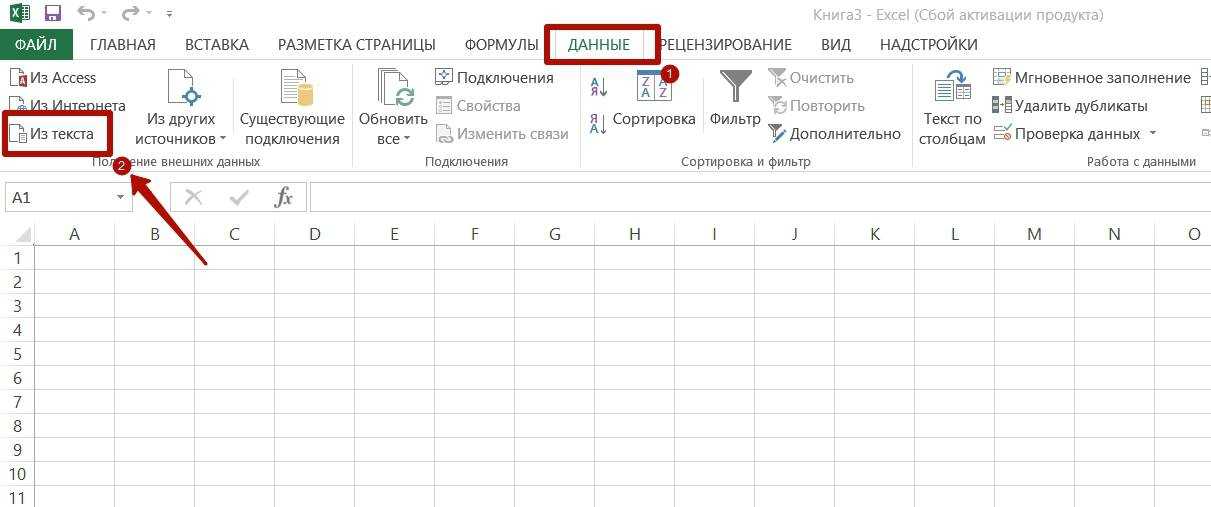
- Перейдите во вкладку «Данные» в строке меню.
- На панели «Получать внешние данные» нажмите «Из текста».
- В списке «Тип файла» (он находится рядом с кнопкой «Отмена») выберите «Все» или «Любые». Так в окне будут отображаться форматы Excel, а не только .txt.
- Задайте путь к таблице.
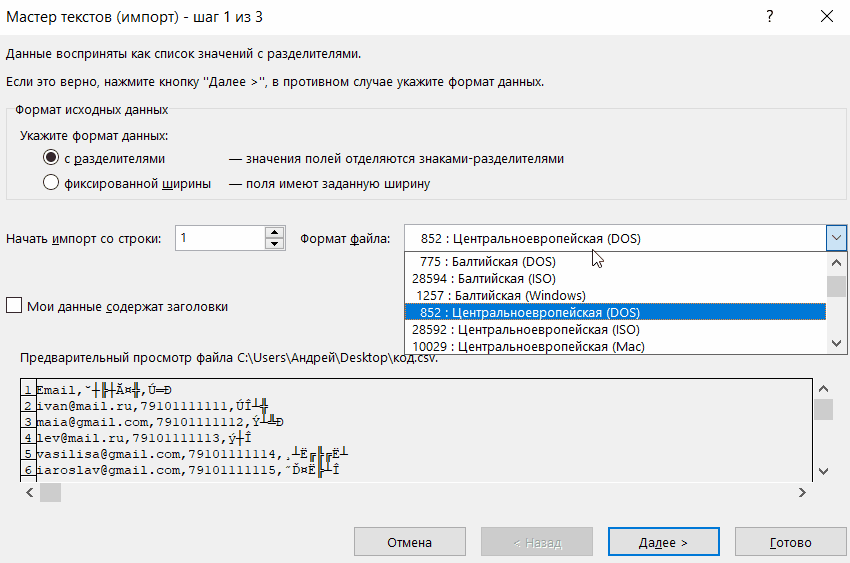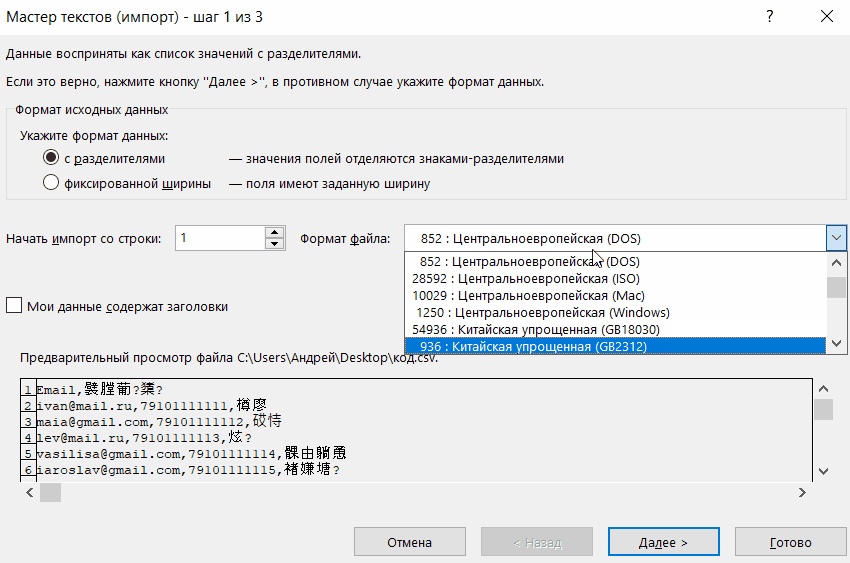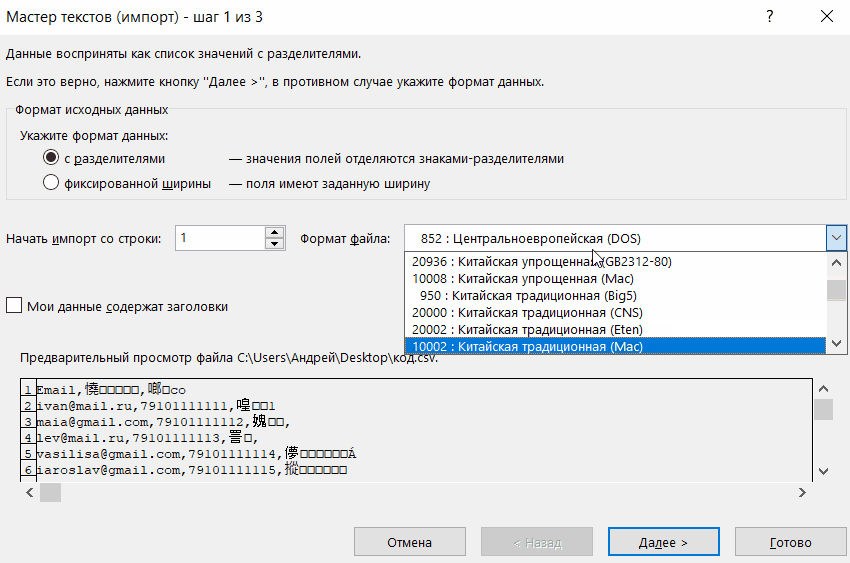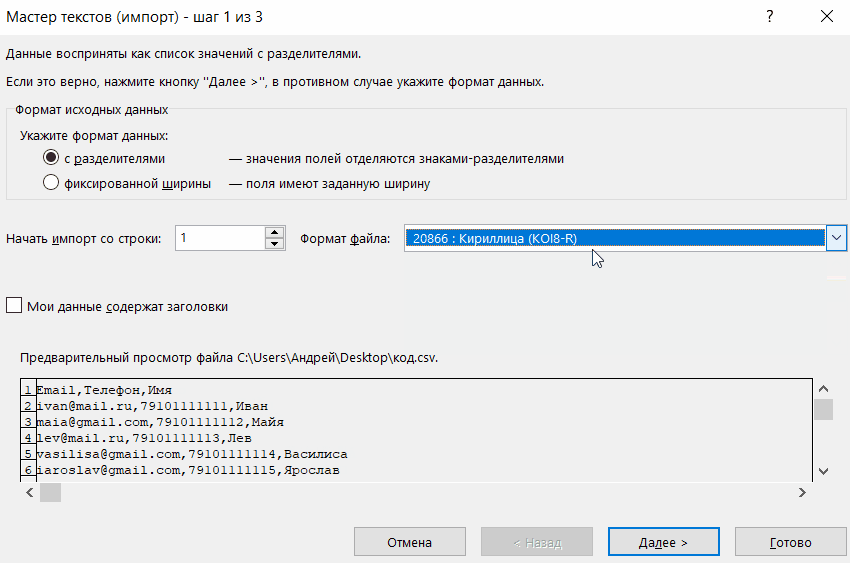
- Откроется мастер импорта.
- В поле «Формат» можете выбрать желаемый стандарт.
- В области «Предварительный просмотр» показано, как будет выглядеть текст с отмеченным набором символов. Можете прокручивать список и искать, какая настройка подходит.
- Когда подберёте нужный вариант, нажмите «Готово».
Можно использовать встроенные возможности
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Источник
Смена кодировки UTF-8 на Windows-1251
Изменение кодировки текста UTF-8 на ANSI (Windows-1251) для 32-разрядных платформ:
|
1 |
PrivateDeclareFunctionMultiByteToWideChar Lib»kernel32.dll»(ByValCodePage AsLong,ByValdwFlags AsLong,ByVallpMultiByteStr AsString,ByValcchMultiByte AsLong,ByVallpWideCharStr AsLong,ByValcchWideChar AsLong)AsLong FunctionFromUTF8(ByValsText AsString)AsString DimnRet AsLong,strRet AsString strRet=String(Len(sText),vbNullChar) nRet=MultiByteToWideChar(65001,&H0,sText,Len(sText),StrPtr(strRet),Len(strRet)) FromUTF8=Left(strRet,nRet) EndFunction |
Пример перекодировки строки с UTF-8 в ANSI (Windows-1251):
|
1 |
SubPrimer() Dimnum1 AsInteger,a1 AsString,str1 AsString ‘Выбираем файл CSV с кодировкой UTF-8 a1=Application.GetOpenFilename(«Текст с разделителями,*.csv»,,»Выбор файла») IfRight(a1,4)<>».csv»ThenExitSub ‘Открываем файл и считываем текст в переменную num1=FreeFile Open a1 ForInput Asnum1 str1=Input(LOF(num1),num1) Close num1 ‘Меняем кодировку с UTF-8 на Windows-1251 str1=FromUTF8(str1) ‘Работаем с текстом и вставляем нужные значения на рабочий лист EndSub |
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции
И третий вариант
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
=>
=>
=>
=>
=>
=>
=>
=>
=>
=>
print_r (mb_str_split(‘Марат’)); выдаст :
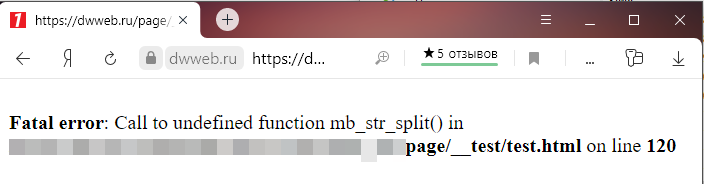
Как видим… полный отстой…



здесь.
Меняем
Начнём с самого простого способа изменить кодировку текста в Блокноте — в процессе сохранения файла!
- Откройте файл txt, в котором хотите изменить кодирование.
- Кликните по вкладке «Файл» наверху.
Теперь кликните «Сохранить как».
Внизу возле пункта «Кодировка» откройте список, нажав на стрелочку.
Выберите один из вариантов и нажмите «Сохранить».
Этот способ подходит, если вы разбираетесь, как сменить кодировку в Блокноте для отдельного файла. Второй способ устанавливает нужную систему по умолчанию — но не текстового редактора, а создаваемых файлов. Рассказываем!
Второй способ
Этот способ сложнее, чем первый — мы узнаем, как в Блокноте поменять кодировку текста через редактор реестра. Возможно, вы никогда раньше не слышали про редактор реестра или не сталкивались с ним. Мы поможем разобраться!
Инструкция состоит из двух этапов: сначала создаём файл-образец, а затем кладём его в редактор реестра. Этот образец будет говорить компьютеру, какую систему кодирования применять к файлу. Поехали!
Откройте Notepad. Это можно сделать через меню «Пуск», раздел «Стандартные».
Нажмите на вкладку «Файл» наверху.
Кликните «Сохранить как».
- Дайте файлу название. Так как это образец, можете для удобства назвать его UTF-8.txt. Проверьте, чтобы стояло именно это расширение!
- Внизу в строке «Кодировка» откройте выпадающий список, нажав на стрелочку, и выберите нужный вариант. Мы меняли ANSI на UTF-8.
- Нажмите «Сохранить».
Образец создан! Теперь займёмся редактором реестра. Если ищете, как поменять кодировку в Блокноте Windows 10 или других версиях этой ОС, есть стандартная утилита Regedit.
- Переместите созданный файл в папку C:WindowsShellNew. Если её нет, создайте.
- Откройте Regedit, можете найти программу в «Поиске» на панели задач.
Идите по пути: HKEY_CLASSES_ROOT/.txt /ShellNew. Опять ж, если конечной папки нет, создайте её.
Теперь создадим строковый параметр. Для этого в папке ShellNew кликните правой кнопкой мыши и нажмите «Строковый параметр».
Назовите параметр именем FileName и добавьте значение параметра. Для этого кликните по нему правой кнопкой мыши и нажмите «Изменить».
В открывшемся окне в строке «Значение» введите UTF-8.txt. Это имя файла-образца, вспомнили?
Готово! Вы справились с самым сложным способом, как исправить кодировку в Блокноте! Теперь в создаваемом файле будет та система, которую вы установили в образце. Тема была актуальна для вас?
Скорее читайте, как найти заметки ВКонтакте и создавать их.